Contextual Visual Feature Learning for Zero-Shot Recognition of Human-Object Interactions
{kind=link}
Abstract
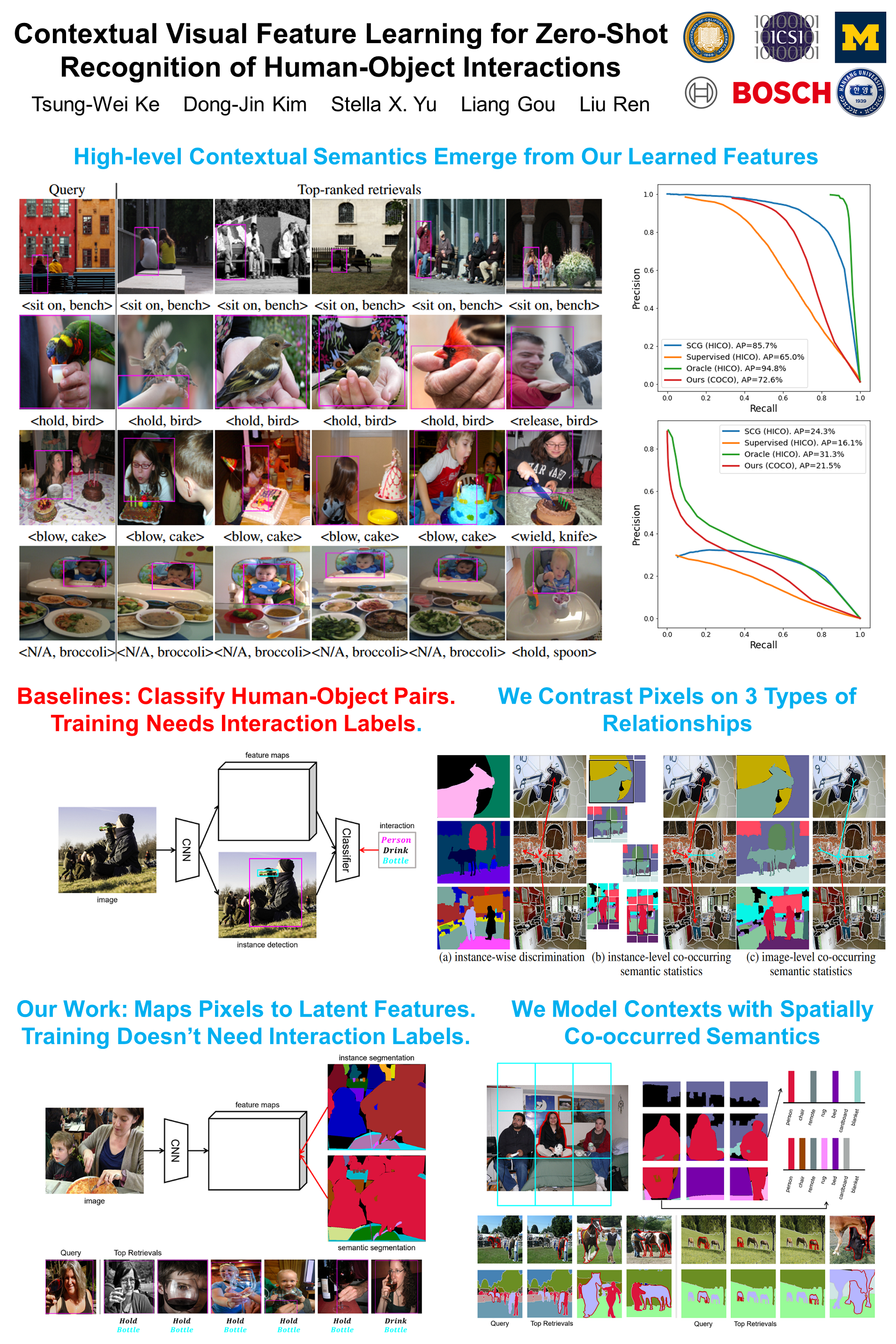
Real-world visual recognition of an object involves not only its own semantics but also those surrounding it. Supervised learning of contextual relationships is restrictive and impractical with the combinatorial explosion of possible relationships among a group of objects. Our key insight is to formulate visual context not as a relationship classification problem, but as a representation learning problem, where objects located close in the feature space have similar visual contexts. Such a model is infinitely scalable with respect to the number of objects or their relationships.We develop a contextual visual feature learning model without any supervision on relationships. We characterize visual context in terms of spatial configuration of semantics between objects and their surrounds, and derive pixel-to-segment learning losses that capture visual similarity, semantic co-occurrences, and structural correlation. Visual context emerges in a completely data-driven fashion, with objects in similar contexts mapped to close points in the feature space. Most strikingly, when benchmarked on HICO for recognizing human-object interactions, our unsupervised model trained only on MSCOCO significantly outperforms the supervised baseline and approaches the supervised state-of-the-art, both trained specifically on HICO with annotated relationships!