Scaling Laws Beyond Backpropagation
{kind=link}
Abstract
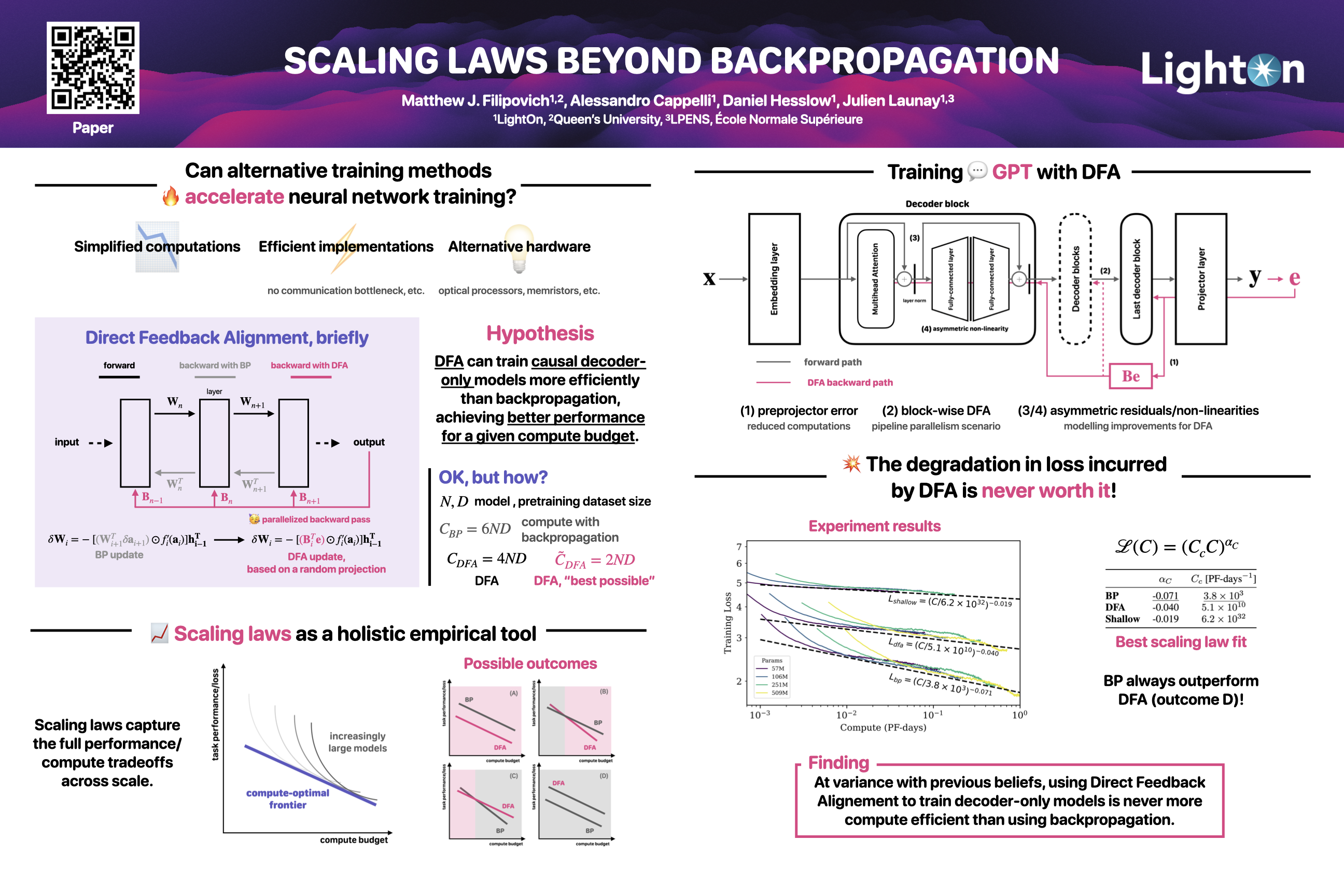
Alternatives to backpropagation have long been studied to better understand how biological brains may learn. Recently, they have also garnered interest as a way to train neural networks more efficiently. By relaxing constraints inherent to backpropagation (e.g., symmetric feedforward and feedback weights, sequential updates), these methods enable promising prospects, such as local learning. However, the tradeoffs between different methods in terms of final task performance, convergence speed, and ultimately compute and data requirements are rarely outlined. In this work, we use scaling laws to study the ability of Direct Feedback Alignment~(DFA) to train causal decoder-only Transformers efficiently. Scaling laws provide an overview of the tradeoffs implied by a modeling decision, up to extrapolating how it might transfer to increasingly large models. We find that DFA fails to offer more efficient scaling than backpropagation: there is never a regime for which the degradation in loss incurred by using DFA is worth the potential reduction in compute budget. Our finding comes at variance with previous beliefs in the alternative training methods community, and highlights the need for holistic empirical approaches to better understand modeling decisions.