DP-InstaHide: Data Augmentations Provably Enhance Guarantees Against Dataset Manipulations
Eitan Borgnia ⋅ Jonas Geiping ⋅ Valeriia Cherepanova ⋅ Liam Fowl ⋅ Arjun Gupta ⋅ Amin Ghiasi ⋅ Furong Huang ⋅ Micah Goldblum ⋅ Tom Goldstein
{kind=link}
Abstract
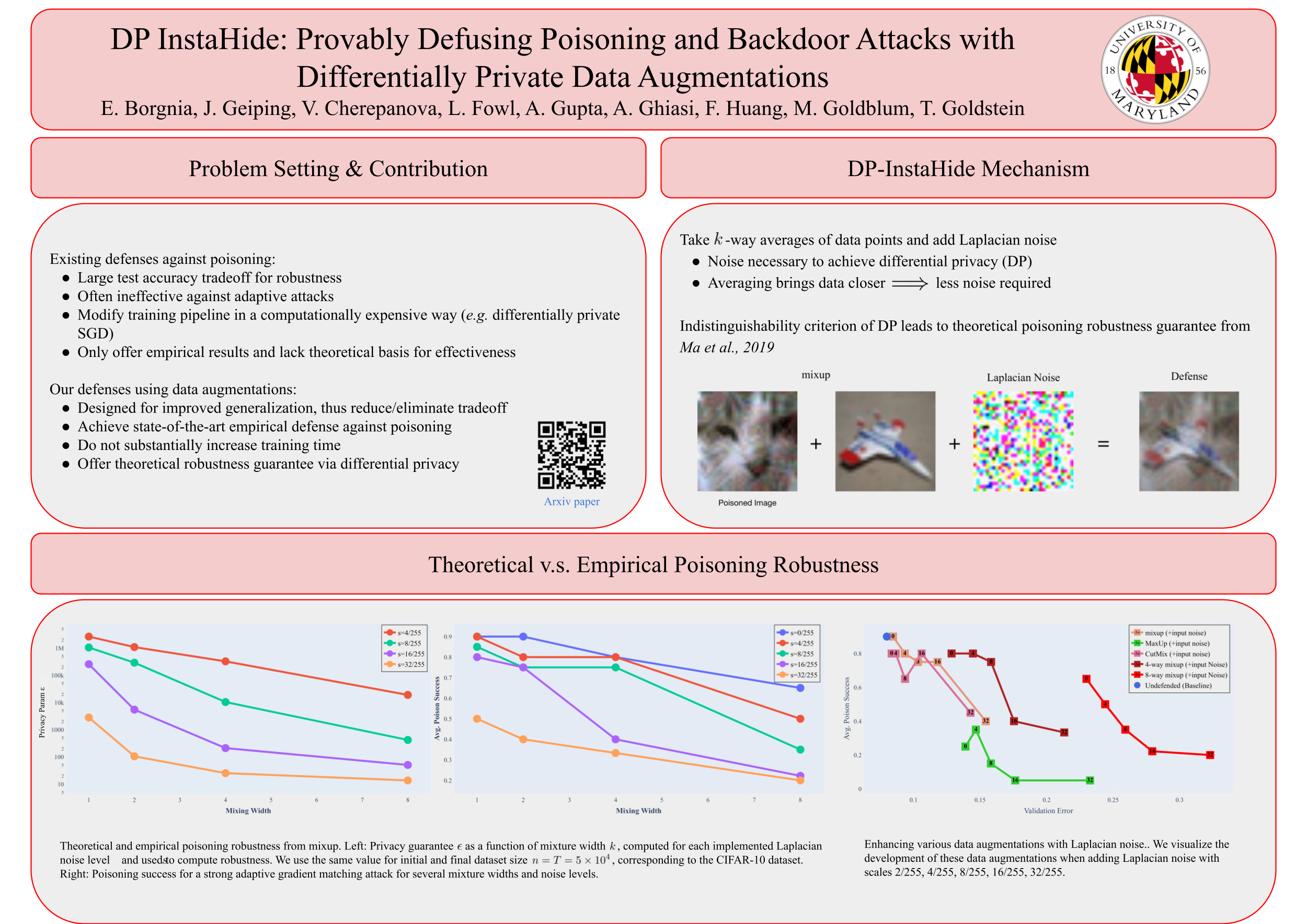
Data poisoning and backdoor attacks manipulate training data to induce security breaches in a victim model. These attacks can be provably deflected using differentially private (DP) training methods, although this comes with a sharp decrease in model performance. The InstaHide method has recently been proposed as an alternative to DP training that leverages supposed privacy properties of the mixup augmentation, although without rigorous guarantees. In this paper, we rigorously show that $k$-way mixup provably yields at least $k$ times stronger DP guarantees than a naive DP mechanism, and we observe that this enhanced privacy guarantee is a strong foundation for building defenses against poisoning.
Chat is not available.
Successful Page Load