A Few Expert Queries Suffices for Sample-Efficient RL with Resets and Linear Value Approximation
Philip Amortila ⋅ Nan Jiang ⋅ Dhruv Madeka ⋅ Dean Foster
Keywords:
sample efficiency
imitation learning
function approximation
linear realizability
Reinforcement Learning
2022 Poster
{kind=link}
Abstract
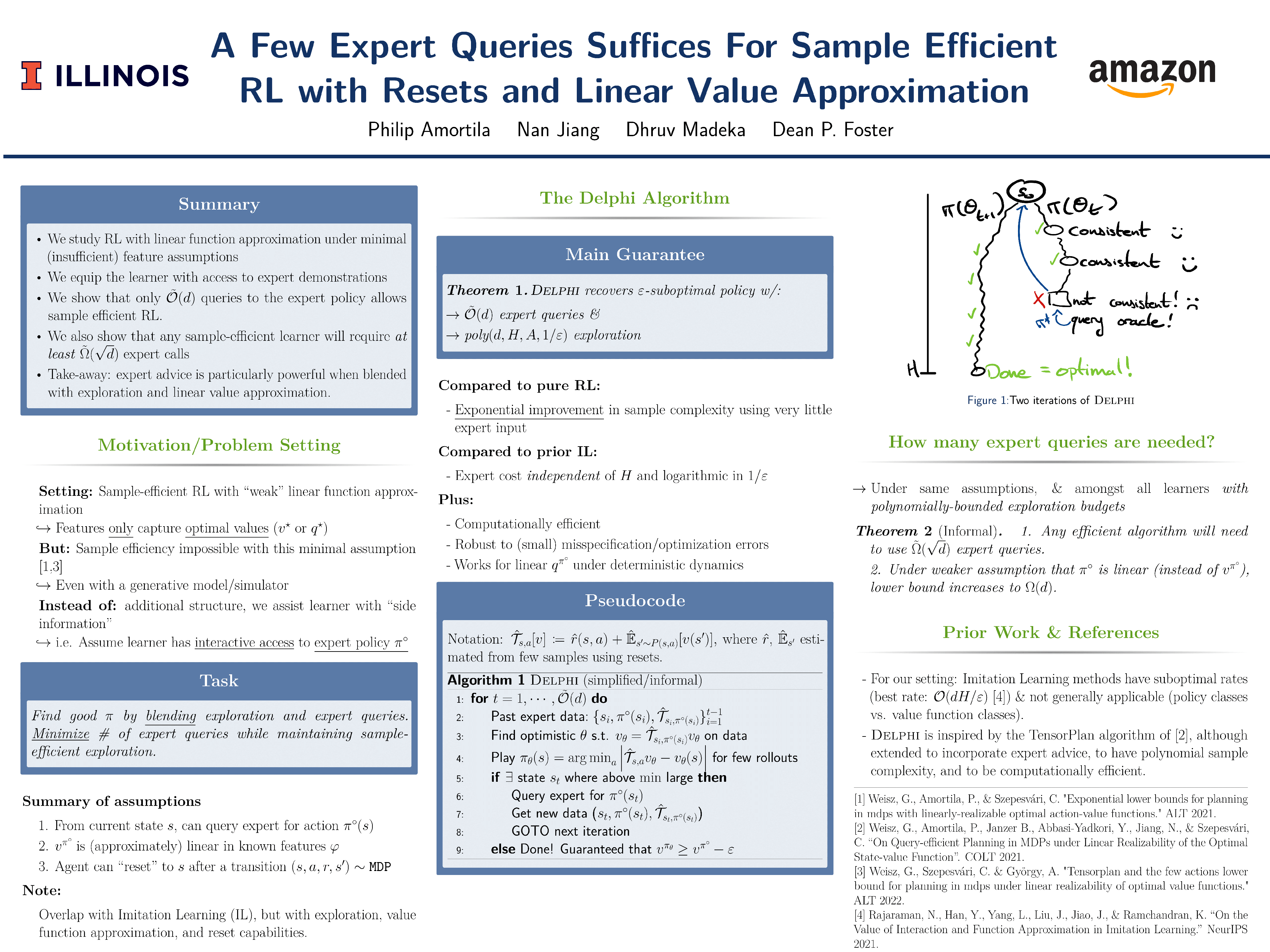
The current paper studies sample-efficient Reinforcement Learning (RL) in settings where only the optimal value function is assumed to be linearly-realizable. It has recently been understood that, even under this seemingly strong assumption and access to a generative model, worst-case sample complexities can be prohibitively (i.e., exponentially) large. We investigate the setting where the learner additionally has access to interactive demonstrations from an expert policy, and we present a statistically and computationally efficient algorithm (Delphi) for blending exploration with expert queries. In particular, Delphi requires $\tilde O(d)$ expert queries and a $\texttt{poly}(d,H,|A|,1/\varepsilon)$ amount of exploratory samples to provably recover an $\varepsilon$-suboptimal policy. Compared to pure RL approaches, this corresponds to an exponential improvement in sample complexity with surprisingly-little expert input. Compared to prior imitation learning (IL) approaches, our required number of expert demonstrations is independent of $H$ and logarithmic in $1/\varepsilon$, whereas all prior work required at least linear factors of both in addition to the same dependence on $d$. Towards establishing the minimal amount of expert queries needed, we show that, in the same setting, any learner whose exploration budget is \textit{polynomially-bounded} (in terms of $d,H,$ and $|A|$) will require \textit{at least} $\tilde\Omega(\sqrt{d})$ oracle calls to recover a policy competing with the expert's value function. Under the weaker assumption that the expert's policy is linear, we show that the lower bound increases to $\tilde\Omega(d)$.
Video
Chat is not available.
Successful Page Load