Mean Estimation with User-level Privacy under Data Heterogeneity
Rachel Cummings ⋅ Vitaly Feldman ⋅ Audra McMillan ⋅ Kunal Talwar
Keywords:
differential privacy
mean estimation
statistical inference
meta analysis
heterogeneous users
heterogeneous data
2022 Poster
{kind=link}
Abstract
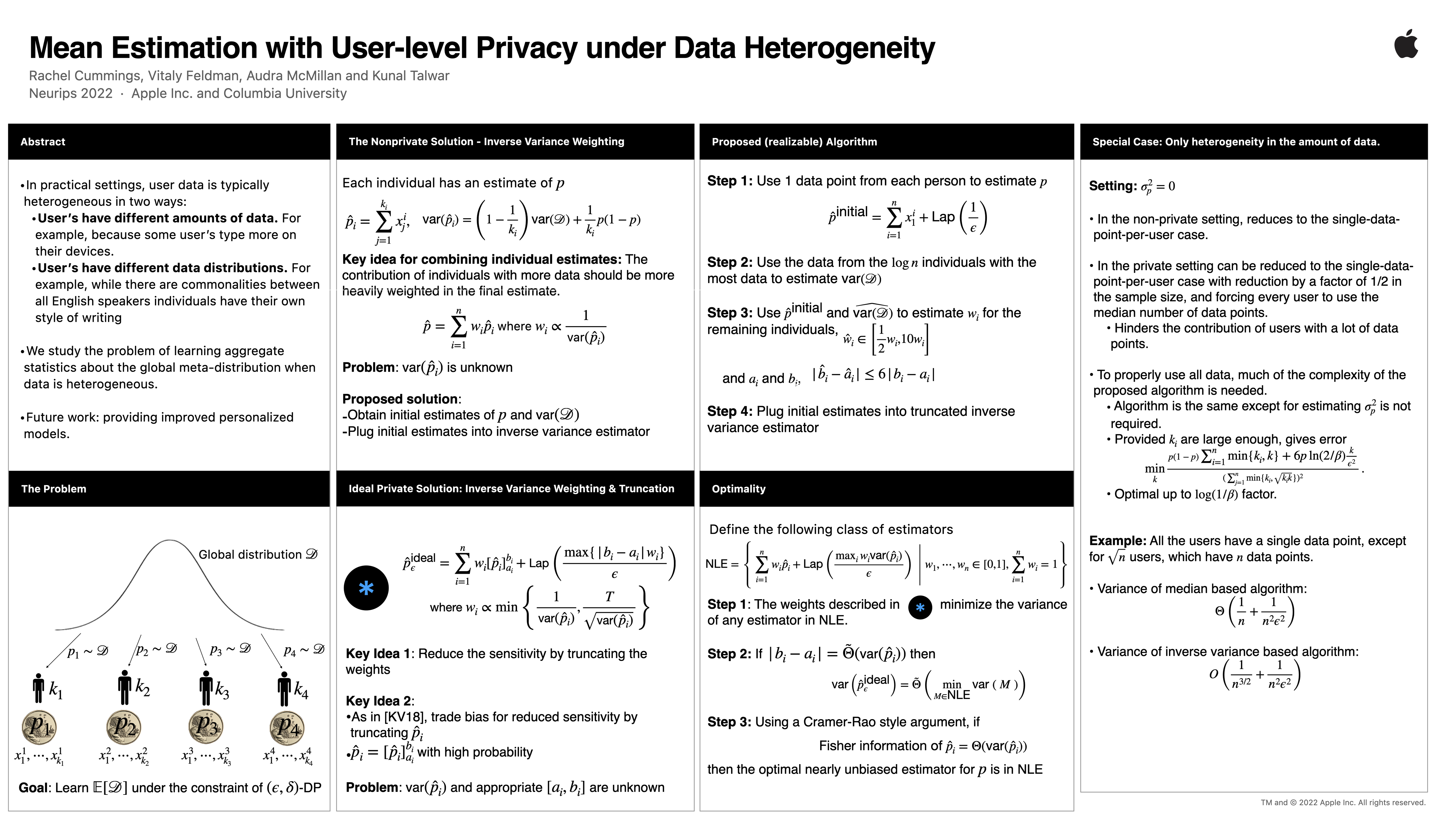
A key challenge in many modern data analysis tasks is that user data is heterogeneous. Different users may possess vastly different numbers of data points. More importantly, it cannot be assumed that all users sample from the same underlying distribution. This is true, for example in language data, where different speech styles result in data heterogeneity. In this work we propose a simple model of heterogeneous user data that differs in both distribution and quantity of data, and we provide a method for estimating the population-level mean while preserving user-level differential privacy. We demonstrate asymptotic optimality of our estimator and also prove general lower bounds on the error achievable in our problem.
Video
Chat is not available.
Successful Page Load