DataMUX: Data Multiplexing for Neural Networks
Vishvak Murahari ⋅ Carlos Jimenez ⋅ Runzhe Yang ⋅ Karthik Narasimhan
2022 Poster
{kind=link}
Abstract
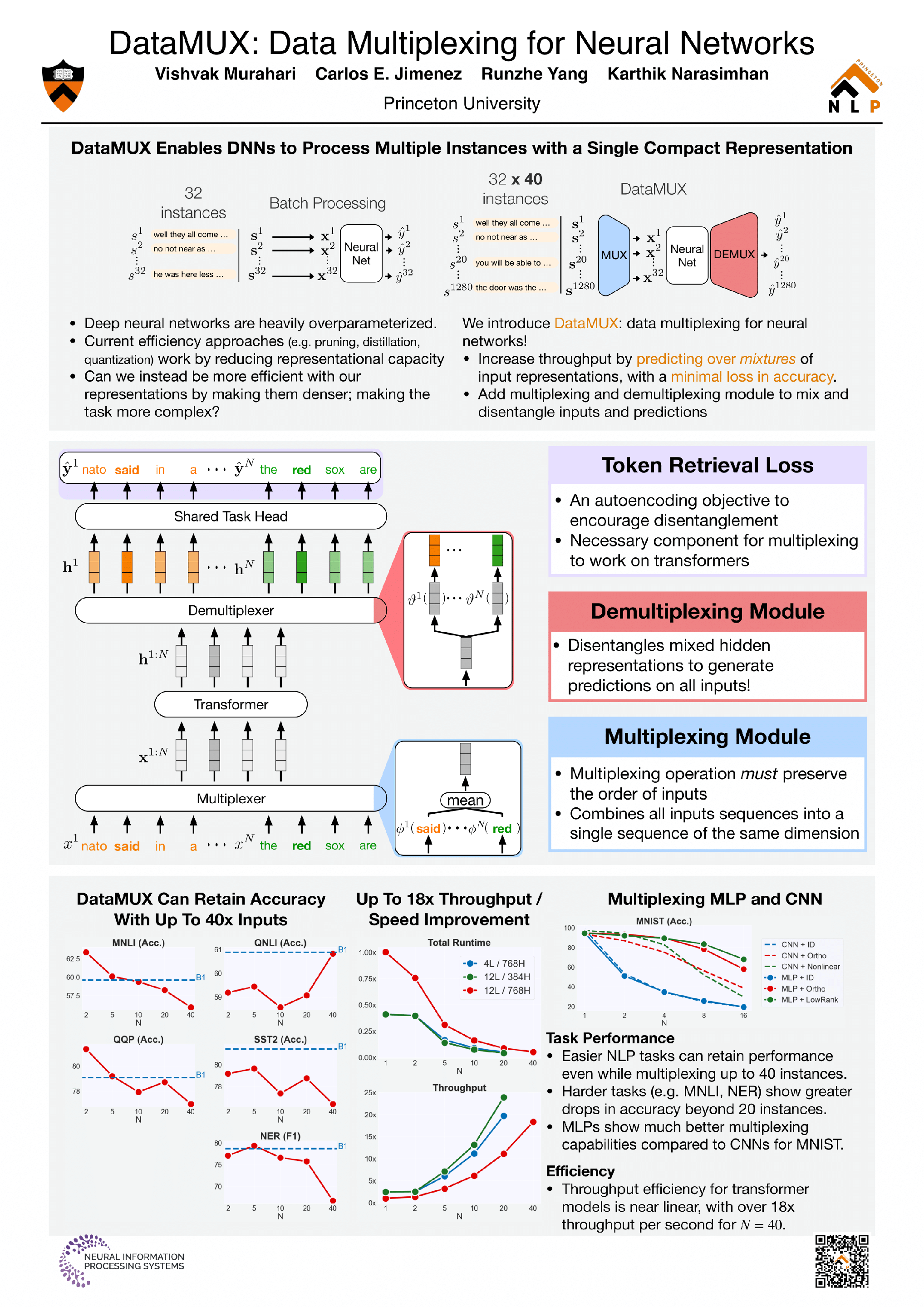
In this paper, we introduce \emph{data multiplexing} (DataMUX), a technique that enables deep neural networks to process multiple inputs simultaneously using a single compact representation. DataMUX demonstrates that neural networks are capable of generating accurate predictions over \emph{mixtures} of inputs, resulting in increased inference throughput with minimal extra memory requirements. Our approach uses two key components -- 1) a multiplexing layer that performs a fixed linear transformation to each input before combining them to create a "mixed" representation of the same size as a single input, which is then processed by the base network, and 2) a demultiplexing layer that converts the base network's output back into independent representations before producing predictions for each input. We show the viability of DataMUX for different architectures (Transformers, and to a much lesser extent MLPs and CNNs) across six different tasks spanning sentence classification, named entity recognition and image classification. For instance, DataMUX for Transformers can multiplex up to 20x/40x inputs, achieving up to 11x/18x increase in inference throughput with absolute performance drops of $<2\%$ and $<4\%$ respectively compared to a vanilla Transformer on MNLI, a natural language inference task. We also provide a theoretical construction for multiplexing in self-attention networks and analyze the effect of various design elements in DataMUX.
Video
Chat is not available.
Successful Page Load