Improved Coresets for Euclidean $k$-Means
Vincent Cohen-Addad ⋅ Kasper Green Larsen ⋅ David Saulpic ⋅ Chris Schwiegelshohn ⋅ Omar Ali Sheikh-Omar
2022 Poster
{kind=link}
Abstract
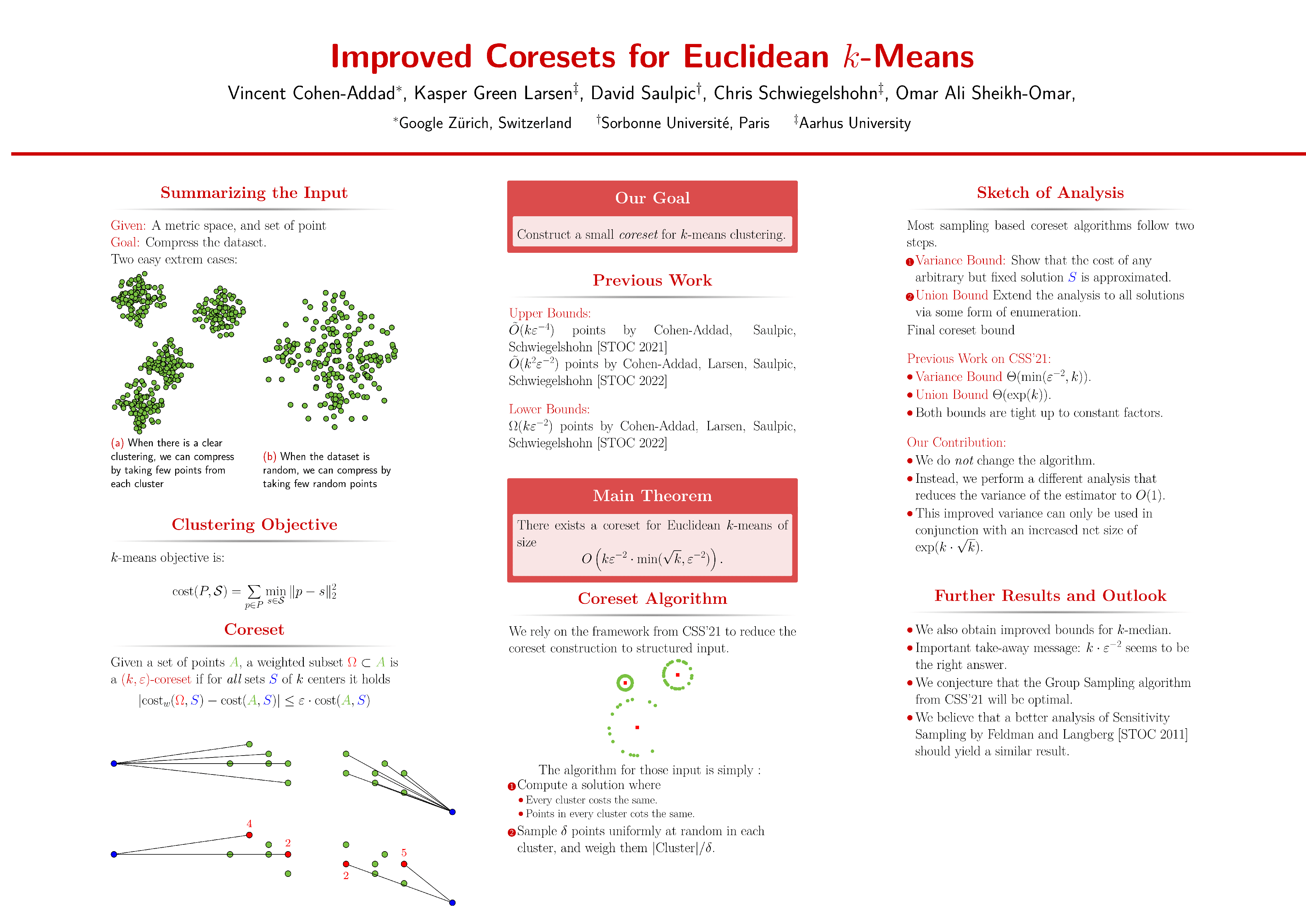
Given a set of $n$ points in $d$ dimensions, the Euclidean $k$-means problem (resp. Euclidean $k$-median) consists of finding $k$ centers such that the sum of squared distances (resp. sum of distances) from every point to its closest center is minimized. The arguably most popular way of dealing with this problem in the big data setting is to first compress the data by computing a weighted subset known as a coreset and then run any algorithm on this subset. The guarantee of the coreset is that for any candidate solution, the ratio between coreset cost and the cost of the original instance is less than a $(1\pm \varepsilon)$ factor. The current state of the art coreset size is $\tilde O(\min(k^{2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-4}))$ for Euclidean $k$-means and $\tilde O(\min(k^{2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-3}))$ for Euclidean $k$-median. The best known lower bound for both problems is $\Omega(k\varepsilon^{-2})$. In this paper, we improve these bounds to $\tilde O(\min(k^{3/2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-4}))$ for Euclidean $k$-means and $\tilde O(\min(k^{4/3} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-3}))$ for Euclidean $k$-median. In particular, ours is the first provable bound that breaks through the $k^2$ barrier while retaining an optimal dependency on $\varepsilon$.
Video
Chat is not available.
Successful Page Load