Information bottleneck theory of high-dimensional regression: relevancy, efficiency and optimality
{kind=link}
Abstract
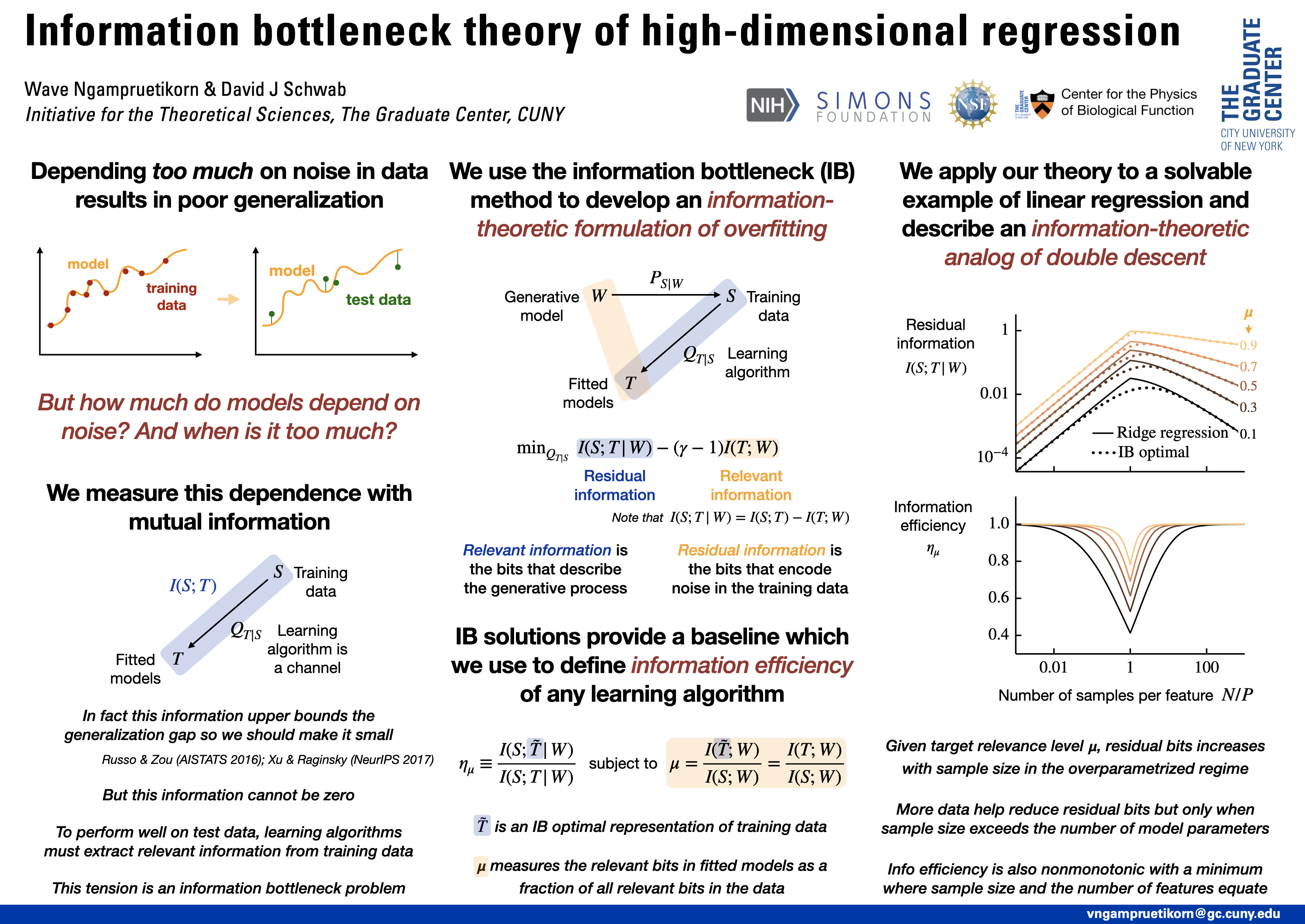
Avoiding overfitting is a central challenge in machine learning, yet many large neural networks readily achieve zero training loss. This puzzling contradiction necessitates new approaches to the study of overfitting. Here we quantify overfitting via residual information, defined as the bits in fitted models that encode noise in training data. Information efficient learning algorithms minimize residual information while maximizing the relevant bits, which are predictive of the unknown generative models. We solve this optimization to obtain the information content of optimal algorithms for a linear regression problem and compare it to that of randomized ridge regression. Our results demonstrate the fundamental trade-off between residual and relevant information and characterize the relative information efficiency of randomized regression with respect to optimal algorithms. Finally, using results from random matrix theory, we reveal the information complexity of learning a linear map in high dimensions and unveil information-theoretic analogs of double and multiple descent phenomena.