Learning to Branch with Tree MDPs
{kind=link}
Abstract
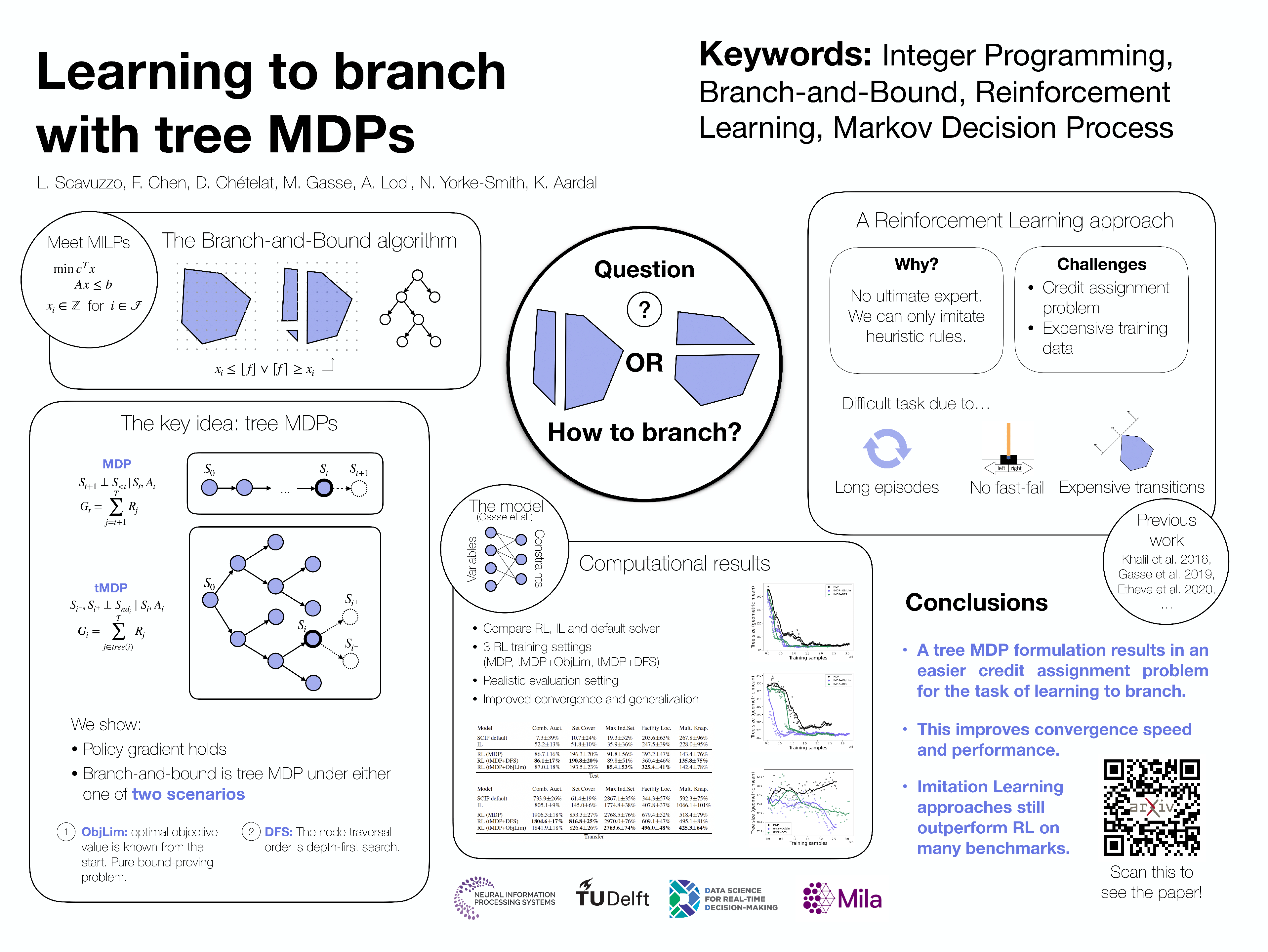
State-of-the-art Mixed Integer Linear Programming (MILP) solvers combine systematic tree search with a plethora of hard-coded heuristics, such as branching rules. While approaches to learn branching strategies have received increasing attention and have shown very promising results, most of the literature focuses on learning fast approximations of the \emph{strong branching} rule. Instead, we propose to learn branching rules from scratch with Reinforcement Learning (RL). We revisit the work of Etheve et al. (2020) and propose a generalization of Markov Decisions Processes (MDP), which we call \emph{tree MDP}, that provides a more suitable formulation of the branching problem. We derive a policy gradient theorem for tree MDPs that exhibits a better credit assignment compared to its temporal counterpart. We demonstrate through computational experiments that this new framework is suitable to tackle the learning-to-branch problem in MILP, and improves the learning convergence.