Bandit Theory and Thompson Sampling-Guided Directed Evolution for Sequence Optimization
Hui Yuan ⋅ Chengzhuo Ni ⋅ Huazheng Wang ⋅ Xuezhou Zhang ⋅ Le Cong ⋅ Csaba Szepesvari ⋅ Mengdi Wang
2022 Poster
{kind=link}
Abstract
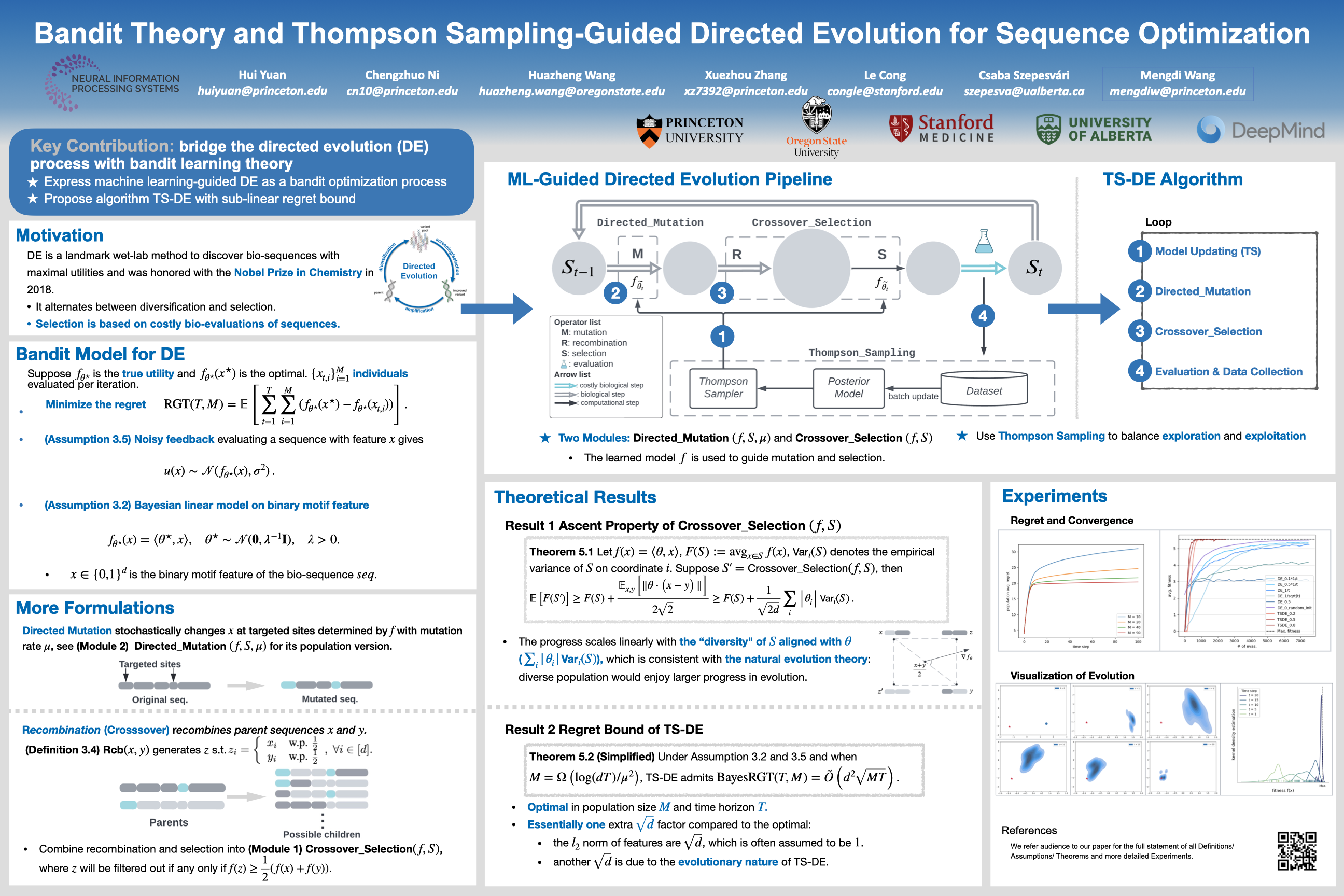
Directed Evolution (DE), a landmark wet-lab method originated in 1960s, enables discovery of novel protein designs via evolving a population of candidate sequences. Recent advances in biotechnology has made it possible to collect high-throughput data, allowing the use of machine learning to map out a protein's sequence-to-function relation. There is a growing interest in machine learning-assisted DE for accelerating protein optimization. Yet the theoretical understanding of DE, as well as the use of machine learning in DE, remains limited.In this paper, we connect DE with the bandit learning theory and make a first attempt to study regret minimization in DE. We propose a Thompson Sampling-guided Directed Evolution (TS-DE) framework for sequence optimization, where the sequence-to-function mapping is unknown and querying a single value is subject to costly and noisy measurements. TS-DE updates a posterior of the function based on collected measurements. It uses a posterior-sampled function estimate to guide the crossover recombination and mutation steps in DE. In the case of a linear model, we show that TS-DE enjoys a Bayesian regret of order $\tilde O(d^{2}\sqrt{MT})$, where $d$ is feature dimension, $M$ is population size and $T$ is number of rounds. This regret bound is nearly optimal, confirming that bandit learning can provably accelerate DE. It may have implications for more general sequence optimization and evolutionary algorithms.
Video
Chat is not available.
Successful Page Load