Globally Gated Deep Linear Networks
Qianyi Li ⋅ Haim Sompolinsky
Keywords:
Gaussian Processes
Kernel Methods
Deep Learning Theory
Finite Width Networks
Gated Linear Networks
Neural Network Architectures
2022 Poster
{kind=link}
Abstract
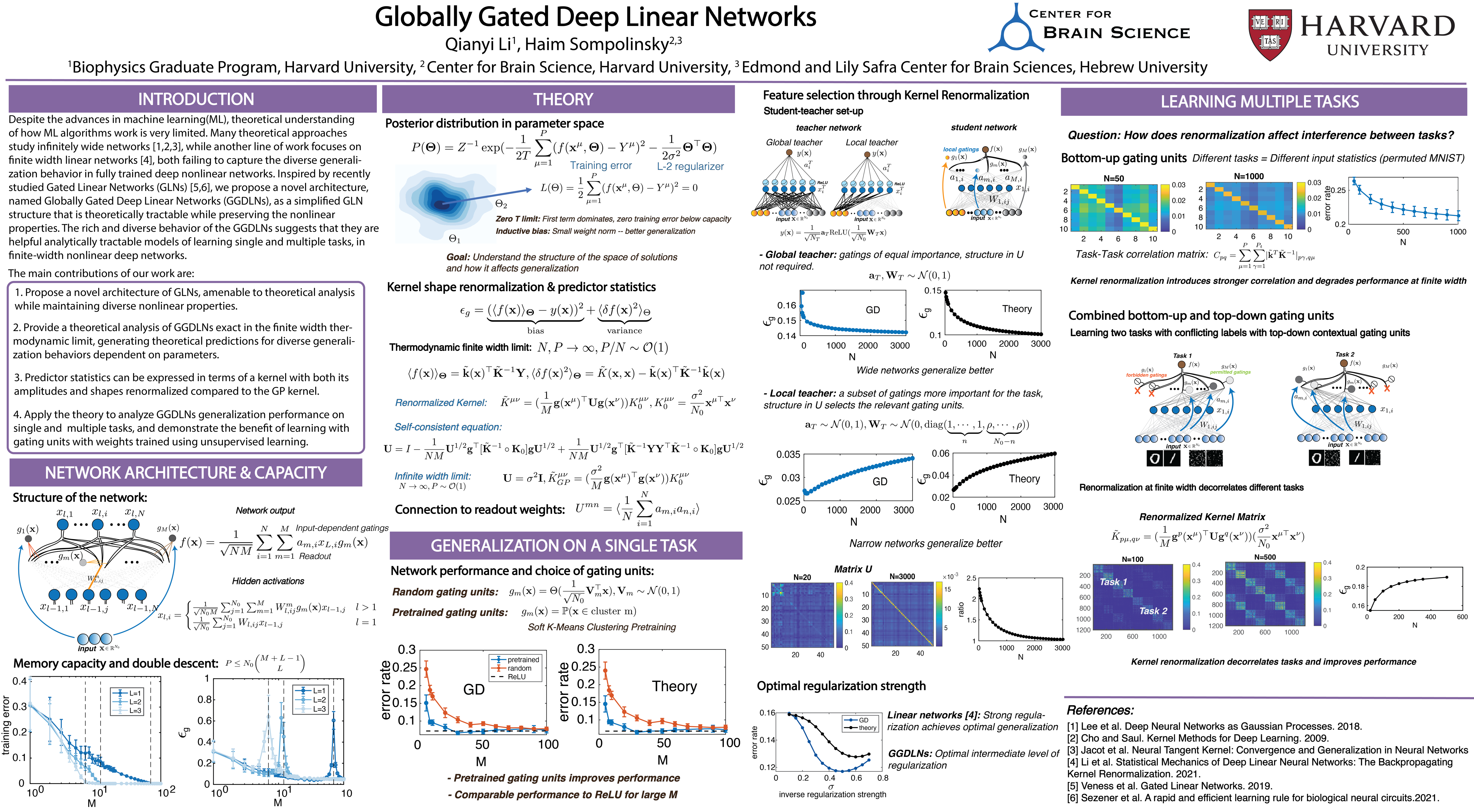
Recently proposed Gated Linear Networks (GLNs) present a tractable nonlinear network architecture, and exhibit interesting capabilities such as learning with local error signals and reduced forgetting in sequential learning. In this work, we introduce a novel gating architecture, named Globally Gated Deep Linear Networks (GGDLNs) where gating units are shared among all processing units in each layer, thereby decoupling the architectures of the nonlinear but unlearned gating and the learned linear processing motifs. We derive exact equations for the generalization properties of Bayesian Learning in these networks in the finite-width thermodynamic limit, defined by $N, P\rightarrow\infty$ while $P/N=O(1)$ where $N$ and $P$ are the hidden layers' width and size of training data sets respectfully. We find that the statistics of the network predictor can be expressed in terms of kernels that undergo shape renormalization through a data-dependent order-parameter matrix compared to the infinite-width Gaussian Process (GP) kernels. Our theory accurately captures the behavior of finite width GGDLNs trained with gradient descent (GD) dynamics. We show that kernel shape renormalization gives rise to rich generalization properties w.r.t. network width, depth, and $L_2$ regularization amplitude. Interestingly, networks with a large number of gating units behave similarly to standard ReLU architectures. Although gating units in the model do not participate in supervised learning, we show the utility of unsupervised learning of the gating parameters. Additionally, our theory allows the evaluation of the network capacity for learning multiple tasks by incorporating task-relevant information into the gating units. In summary, our work is the first exact theoretical solution of learning in a family of nonlinear networks with finite width. The rich and diverse behavior of the GGDLNs suggests that they are helpful analytically tractable models of learning single and multiple tasks, in finite-width nonlinear deep networks.
Video
Chat is not available.
Successful Page Load