Sparse Winning Tickets are Data-Efficient Image Recognizers
{kind=link}
Abstract
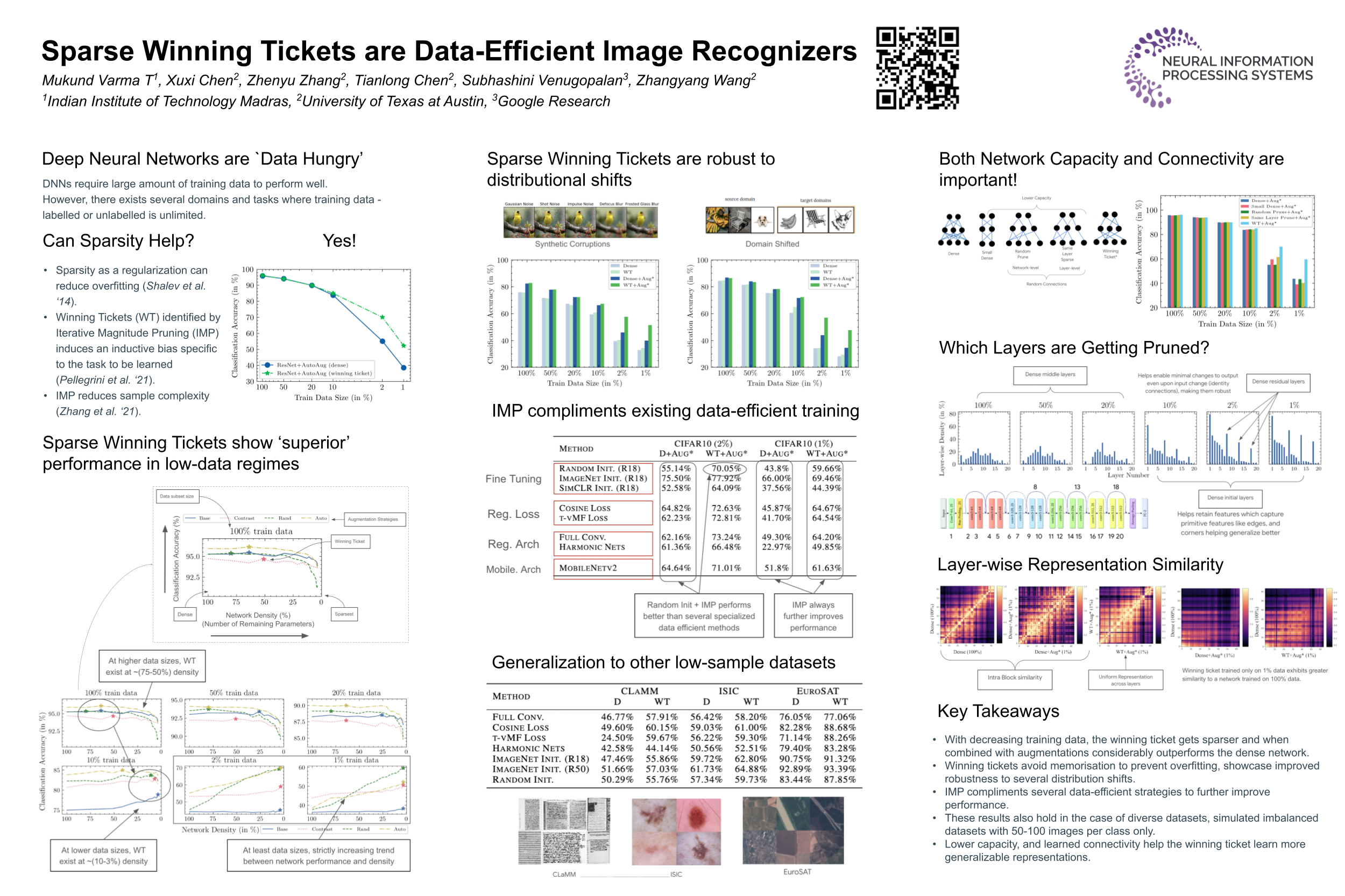
Improving the performance of deep networks in data-limited regimes has warranted much attention. In this work, we empirically show that “winning tickets” (small sub-networks) obtained via magnitude pruning based on the lottery ticket hypothesis, apart from being sparse are also effective recognizers in data-limited regimes. Based on extensive experiments, we find that in low data regimes (datasets of 50-100 examples per class), sparse winning tickets substantially outperform the original dense networks. This approach, when combined with augmentations or fine-tuning from a self-supervised backbone network, shows further improvements in performance by as much as 16% (absolute) on low-sample datasets and long-tailed classification. Further, sparse winning tickets are more robust to synthetic noise and distribution shifts compared to their dense counterparts. Our analysis of winning tickets on small datasets indicates that, though sparse, the networks retain density in the initial layers and their representations are more generalizable. Code is available at https://github.com/VITA-Group/DataEfficientLTH.