Alleviating Adversarial Attacks on Variational Autoencoders with MCMC
Anna Kuzina ⋅ Max Welling ⋅ Jakub Tomczak
2022 Poster
{kind=link}
Abstract
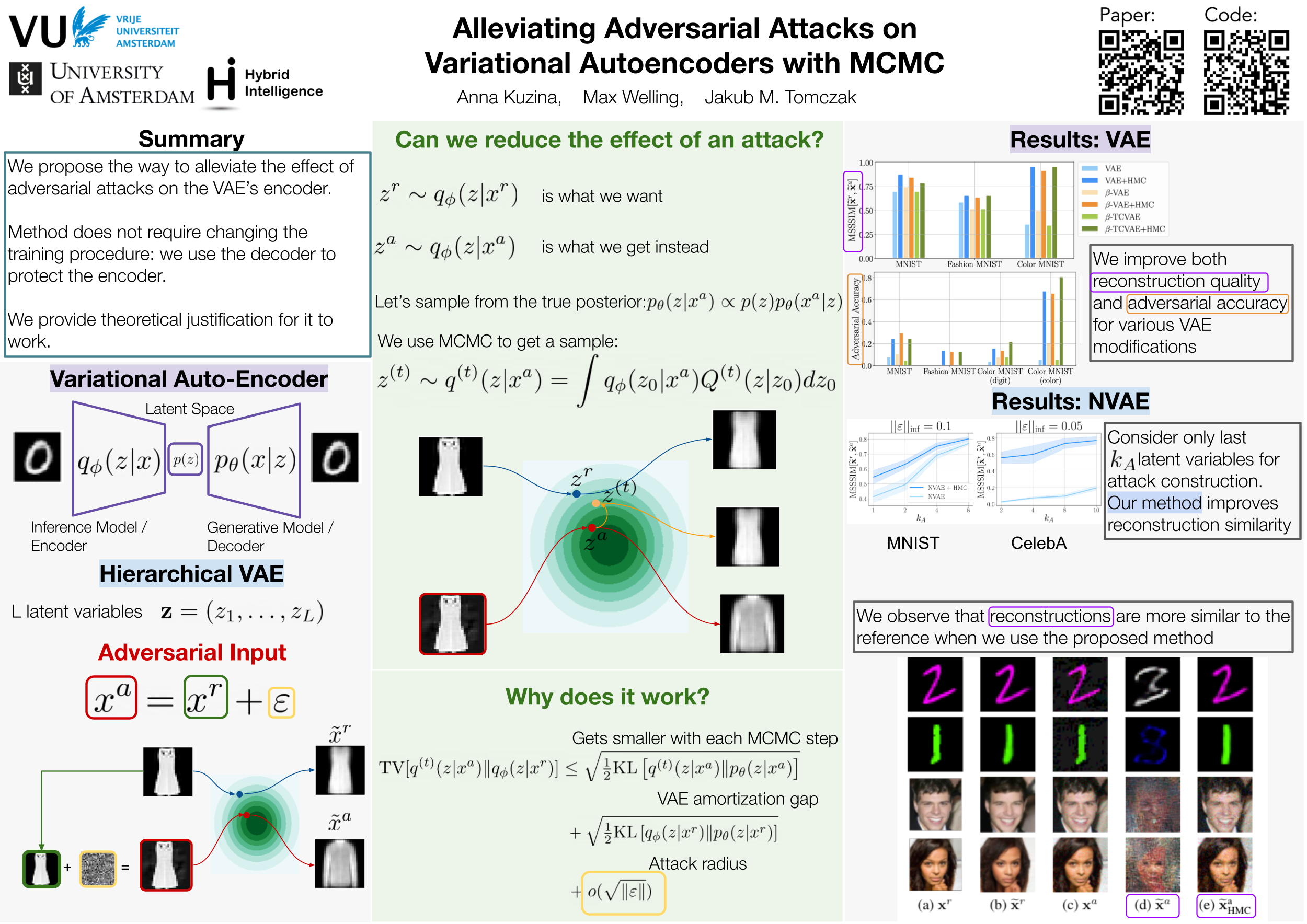
Variational autoencoders (VAEs) are latent variable models that can generate complex objects and provide meaningful latent representations. Moreover, they could be further used in downstream tasks such as classification. As previous work has shown, one can easily fool VAEs to produce unexpected latent representations and reconstructions for a visually slightly modified input. Here, we examine several objective functions for adversarial attacks construction proposed previously and present a solution to alleviate the effect of these attacks. Our method utilizes the Markov Chain Monte Carlo (MCMC) technique in the inference step that we motivate with a theoretical analysis. Thus, we do not incorporate any extra costs during training and the performance on non-attacked inputs is not decreased. We validate our approach on a variety of datasets (MNIST, Fashion MNIST, Color MNIST, CelebA) and VAE configurations ($\beta$-VAE, NVAE, $\beta$-TCVAE), and show that our approach consistently improves the model robustness to adversarial attacks.
Video
Chat is not available.
Successful Page Load