Non-Gaussian Tensor Programs
{kind=link}
Abstract
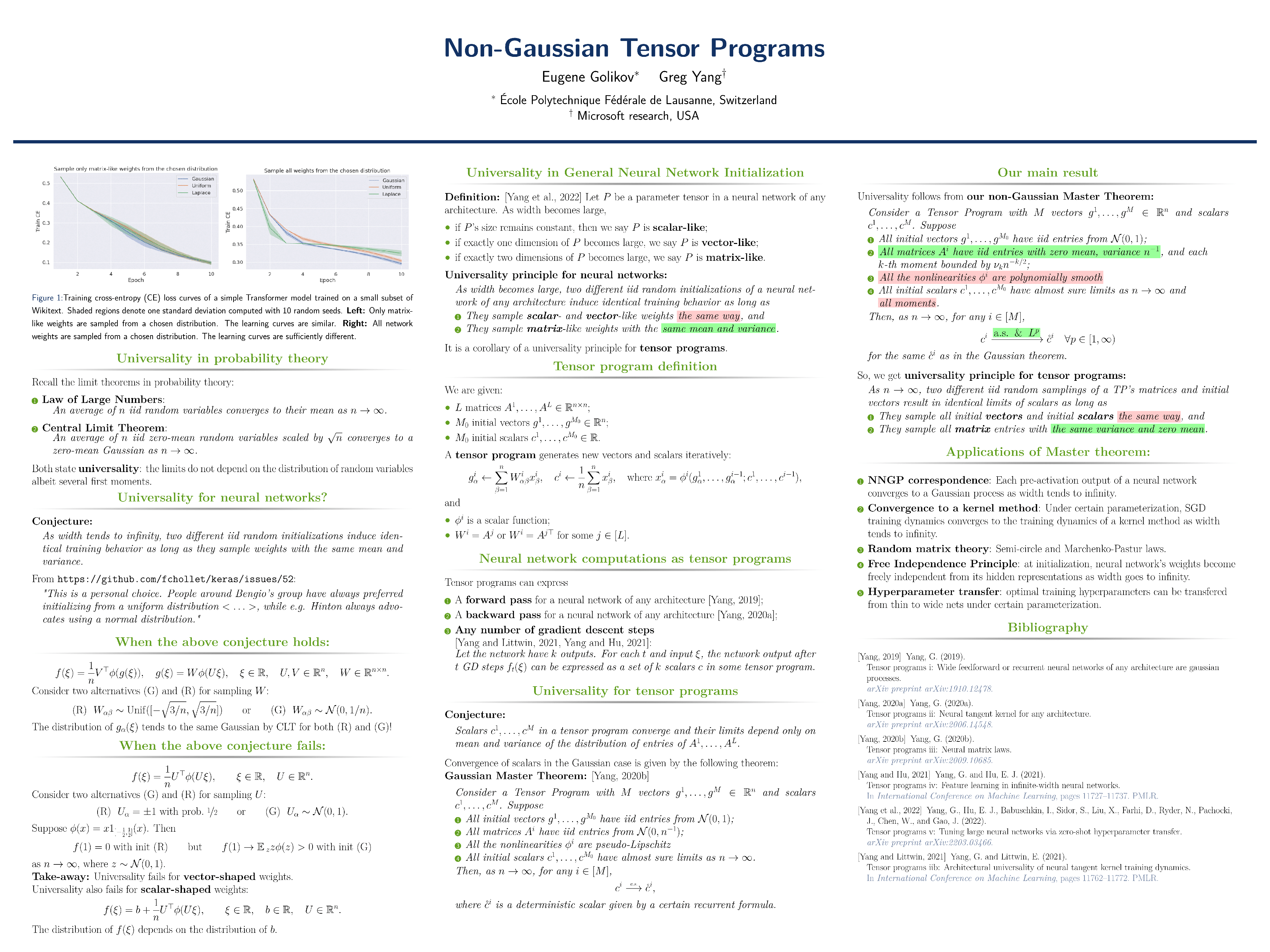
Does it matter whether one randomly initializes a neural network (NN) from Gaussian, uniform, or other distributions? We show the answer is ”yes” in some parameter tensors (the so-called matrix-like parameters) but ”no” in others when the NN is wide. This is a specific instance of a more general universality principle for Tensor Programs (TP) that informs precisely when the limit of a program depends on the distribution of its initial matrices and vectors. To obtain this principle, we develop the theory of non-Gaussian Tensor Programs. As corollaries, we obtain all previous consequences of the TP framework (such as NNGP/NTK correspondence, Free Independence Principle, Dynamical Dichotomy Theorem, and μ-parametrization) for NNs with non-Gaussian weights.