What I Cannot Predict, I Do Not Understand: A Human-Centered Evaluation Framework for Explainability Methods
Julien Colin ⋅ Thomas FEL ⋅ Remi Cadene ⋅ Thomas Serre
2022 Poster
{kind=link}
Abstract
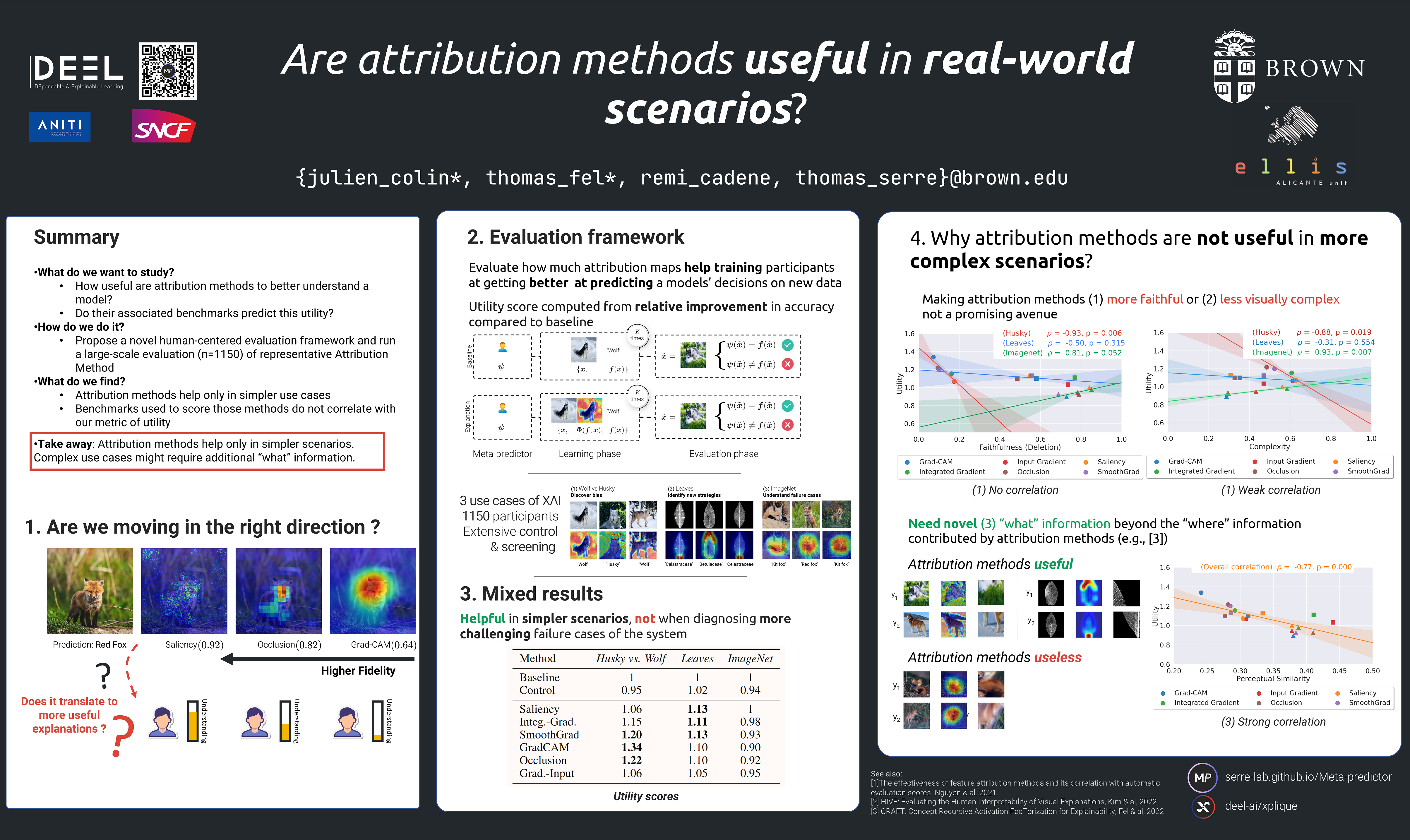
A multitude of explainability methods has been described to try to help users better understand how modern AI systems make decisions. However, most performance metrics developed to evaluate these methods have remained largely theoretical -- without much consideration for the human end-user. In particular, it is not yet clear (1) how useful current explainability methods are in real-world scenarios; and (2) whether current performance metrics accurately reflect the usefulness of explanation methods for the end user. To fill this gap, we conducted psychophysics experiments at scale ($n=1,150$) to evaluate the usefulness of representative attribution methods in three real-world scenarios. Our results demonstrate that the degree to which individual attribution methods help human participants better understand an AI system varies widely across these scenarios. This suggests the need to move beyond quantitative improvements of current attribution methods, towards the development of complementary approaches that provide qualitatively different sources of information to human end-users.
Video
Chat is not available.
Successful Page Load