Unravelling the Performance of Physics-informed Graph Neural Networks for Dynamical Systems
{kind=link}
Abstract
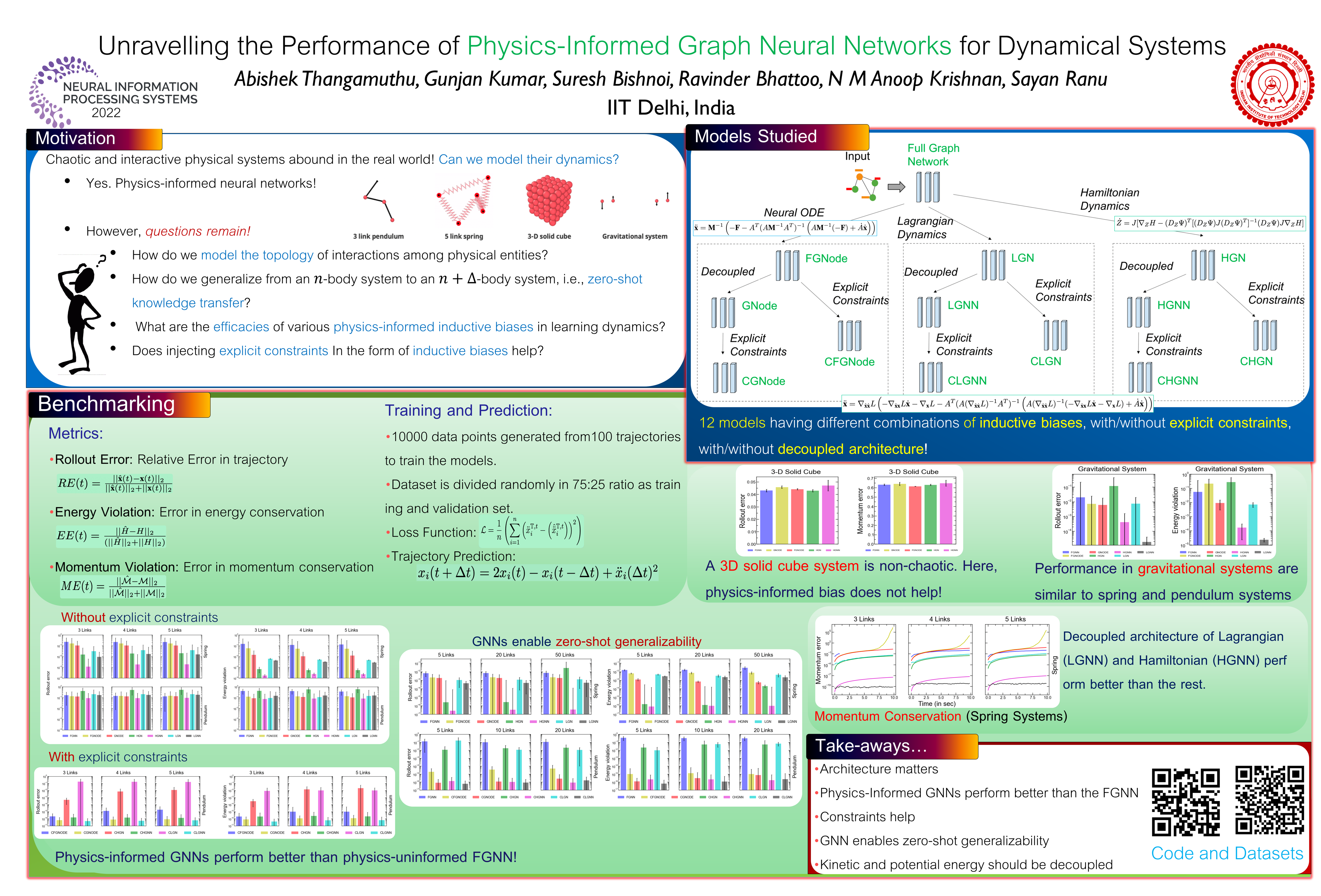
Recently, graph neural networks have been gaining a lot of attention to simulate dynamical systems due to their inductive nature leading to zero-shot generalizability. Similarly, physics-informed inductive biases in deep-learning frameworks have been shown to give superior performance in learning the dynamics of physical systems. There is a growing volume of literature that attempts to combine these two approaches. Here, we evaluate the performance of thirteen different graph neural networks, namely, Hamiltonian and Lagrangian graph neural networks, graph neural ODE, and their variants with explicit constraints and different architectures. We briefly explain the theoretical formulation highlighting the similarities and differences in the inductive biases and graph architecture of these systems. Then, we evaluate them on spring, pendulum, and gravitational and 3D deformable solid systems to compare the performance in terms of rollout error, conserved quantities such as energy and momentum, and generalizability to unseen system sizes. Our study demonstrates that GNNs with additional inductive biases, such as explicit constraints and decoupling of kinetic and potential energies, exhibit significantly enhanced performance. Further, all the physics-informed GNNs exhibit zero-shot generalizability to system sizes an order of magnitude larger than the training system, thus providing a promising route to simulate large-scale realistic systems.