WinoGAViL: Gamified Association Benchmark to Challenge Vision-and-Language Models
{kind=link}
Abstract
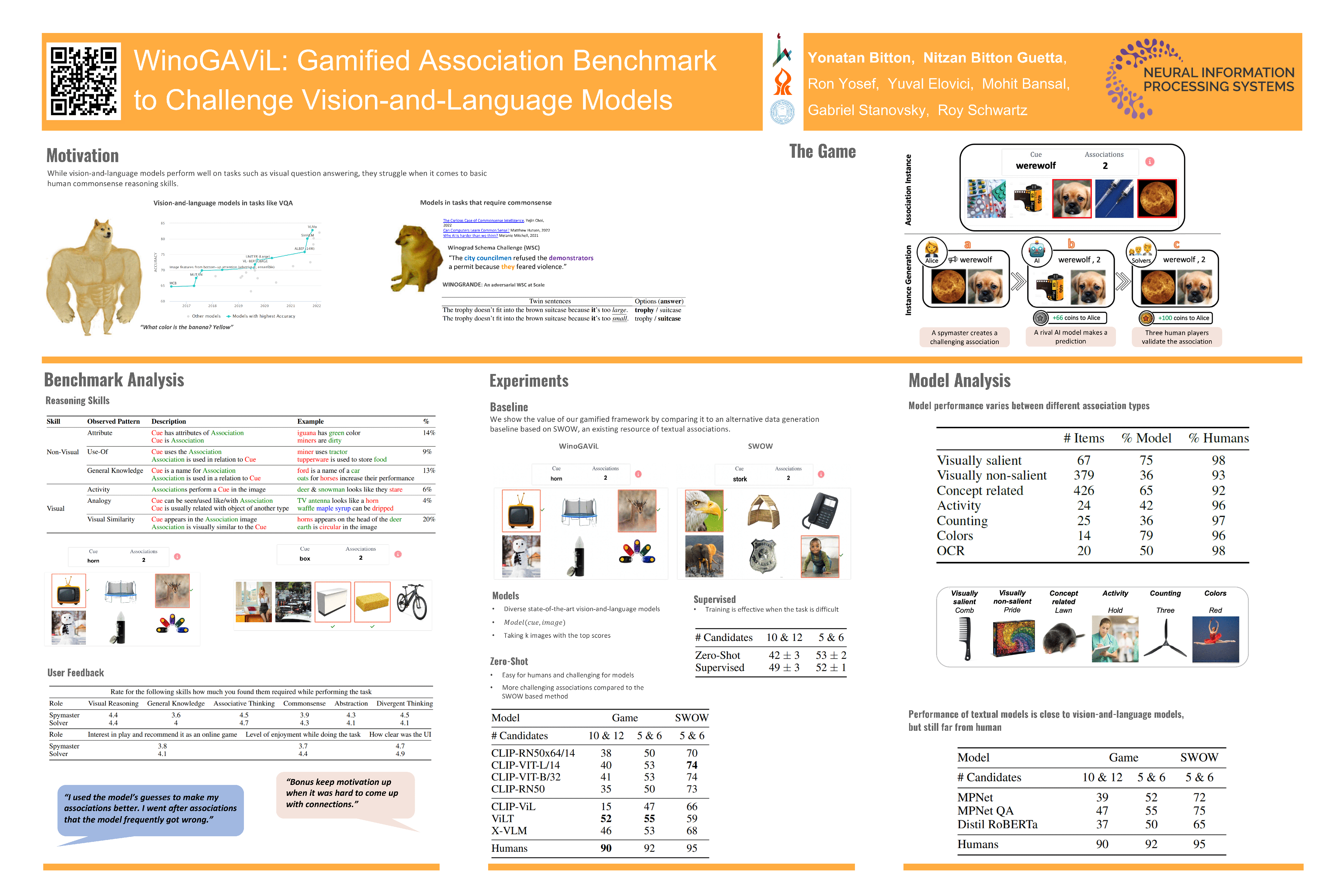
While vision-and-language models perform well on tasks such as visual question answering, they struggle when it comes to basic human commonsense reasoning skills. In this work, we introduce WinoGAViL: an online game of vision-and-language associations (e.g., between werewolves and a full moon), used as a dynamic evaluation benchmark. Inspired by the popular card game Codenames, a spymaster gives a textual cue related to several visual candidates, and another player tries to identify them. Human players are rewarded for creating associations that are challenging for a rival AI model but still solvable by other human players. We use the game to collect 3.5K instances, finding that they are intuitive for humans (>90% Jaccard index) but challenging for state-of-the-art AI models, where the best model (ViLT) achieves a score of 52%, succeeding mostly where the cue is visually salient. Our analysis as well as the feedback we collect from players indicate that the collected associations require diverse reasoning skills, including general knowledge, common sense, abstraction, and more. We release the dataset, the code and the interactive game, allowing future data collection that can be used to develop models with better association abilities.