VeriDark: A Large-Scale Benchmark for Authorship Verification on the Dark Web
{kind=link}
Abstract
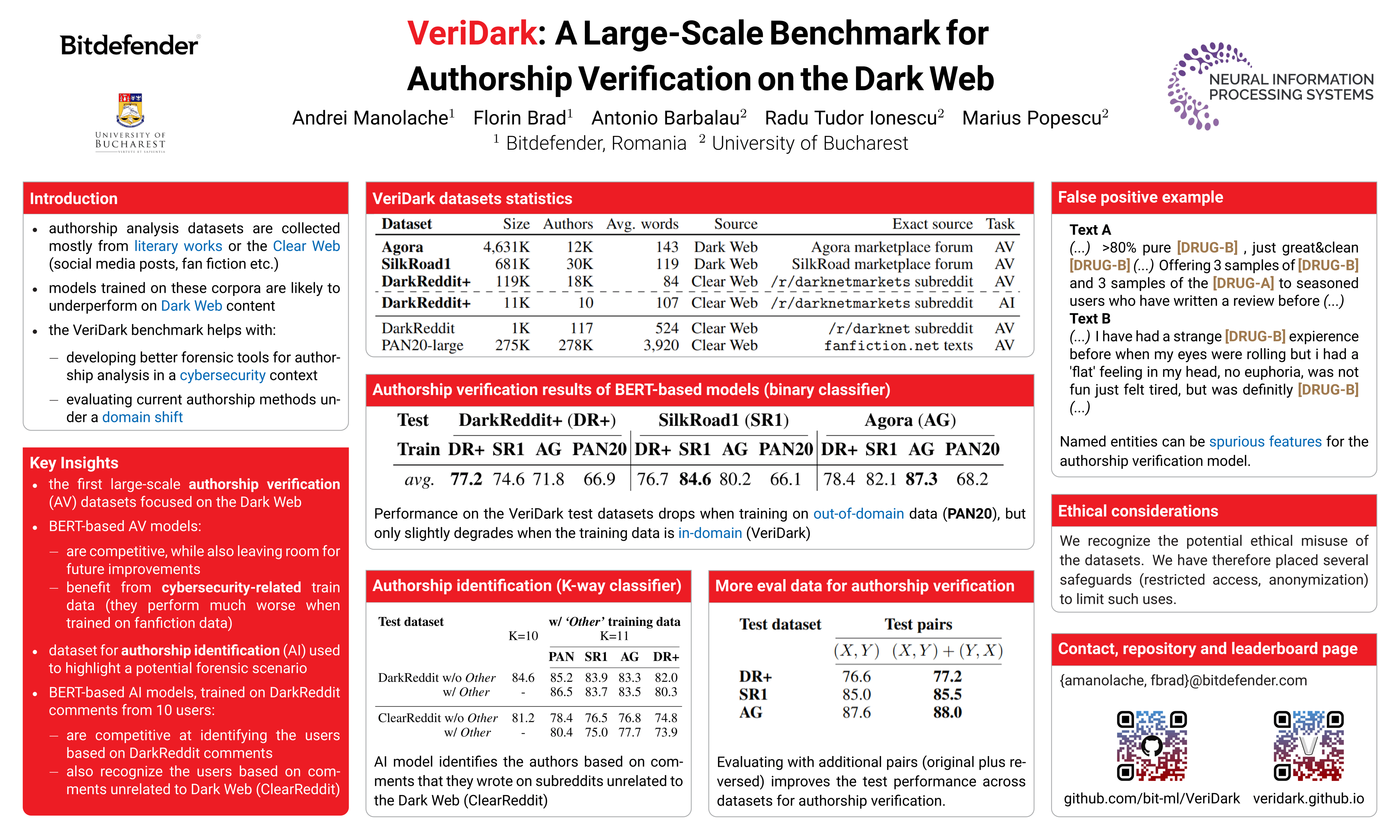
The Dark Web represents a hotbed for illicit activity, where users communicate on different market forums in order to exchange goods and services. Law enforcement agencies benefit from forensic tools that perform authorship analysis, in order to identify and profile users based on their textual content. However, authorship analysis has been traditionally studied using corpora featuring literary texts such as fragments from novels or fan fiction, which may not be suitable in a cybercrime context. Moreover, the few works that employ authorship analysis tools for cybercrime prevention usually employ ad-hoc experimental setups and datasets. To address these issues, we release VeriDark: a benchmark comprised of three large scale authorship verification datasets and one authorship identification dataset obtained from user activity from either Dark Web related Reddit communities or popular illicit Dark Web market forums. We evaluate competitive NLP baselines on the three datasets and perform an analysis of the predictions to better understand the limitations of such approaches. We make the datasets and baselines publicly available at https://github.com/bit-ml/VeriDark .