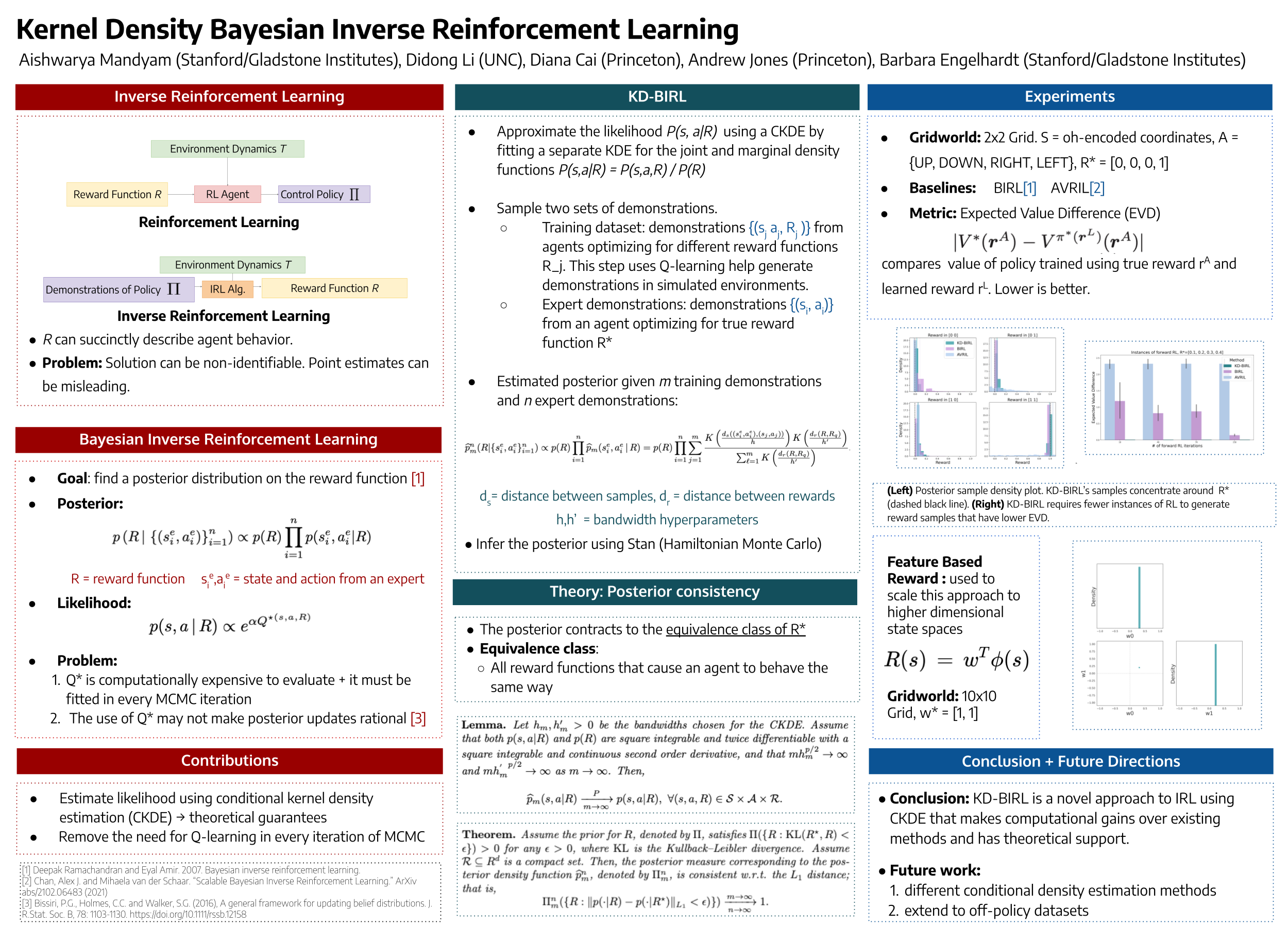
Kernel Density Bayesian Inverse Reinforcement Learning
{kind=link}
Abstract
Inverse reinforcement learning (IRL) is a powerful framework for learning the reward function of an RL agent by observing its behavior. The earliest IRL algorithms were used to infer point estimates of the reward function, but these can be misleading when several reward functions can accurately describe an agent's behavior. In contrast, A Bayesian approach to IRL models a distribution over possible reward functions that explain the set of observations, alleviating the shortcomings of learning a single point estimate. However, most Bayesian IRL algorithms estimate the likelihood using a Q-value function that best approximates the long-term expected reward for a given state-action pair. This can be computationally demanding because it requires solving a Markov Decision Process (MDP) in every iteration of Markov chain Monte Carlo (MCMC) sampling. In response, we introduce kernel density Bayesian inverse reinforcement learning (KD-BIRL), a method that (1) uses kernel density estimation for the likelihood, leading to theoretical guarantees on the resulting posterior distribution, and (2) disassociates the number of times Q-learning is required with the number of iterations of MCMC sampling.