The Lean Data Scientist: Recent Advances towards Overcoming the Data Bottleneck
{kind=link}
Abstract
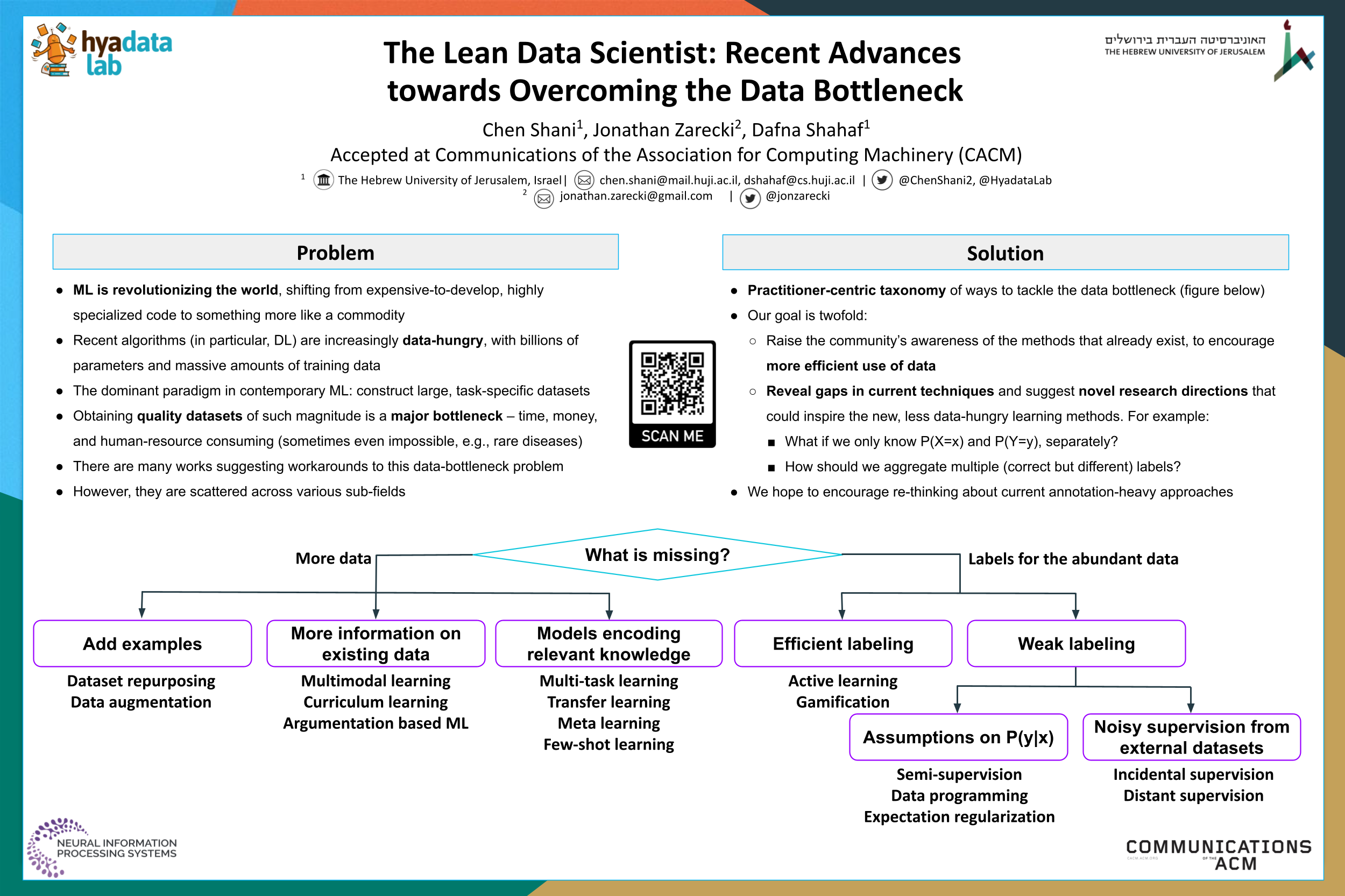
Machine learning (ML) is revolutionizing the world, affecting almost every field of science and industry.A major bottleneck in many ML applications is obtaining data, whereas the rise of deep learning has further exacerbated this issue. Contemporary state of the art models involve millions (or even billions) of parameters and require massive amounts of data to train. Thus, the dominant learning paradigm today is based on creating a new (large) dataset whenever facing a novel task. While this approach resulted in significant advances, it suffers from a major caveat, as collecting large, high-quality datasets is often very demanding in terms of time and human resources (whereas in some cases it is impossible, e.g., rare disease detection). Moreover, while there has been much effort suggestingworkarounds to this data-bottleneck problem, they are scattered across many different sub-fields, often unaware of one another.We aim to bring order to this area by presenting a simple yet comprehensive taxonomy of ways to tackle the data bottleneck (see Figure below). We survey major research directions and organize them into a taxonomy in a practitioner centric manner. Our emphasis is not on covering methods in depth; rather, we discuss the main ideas behind various methods, the assumptions they make and their underlying concepts. For each topic, we mention several important or interesting works, and refer to surveys where possible. We wish to first raise awareness of the methods that already exist, to encourage more efficient use of data. In addition, we hope the taxonomy would also reveal gaps in current techniques and suggest novel research directions that could inspire the new, less data-hungry learning methods.