On Learning Multi-Modal Forgery Representation for Diffusion Generated Video Detection
{kind=link}
Abstract
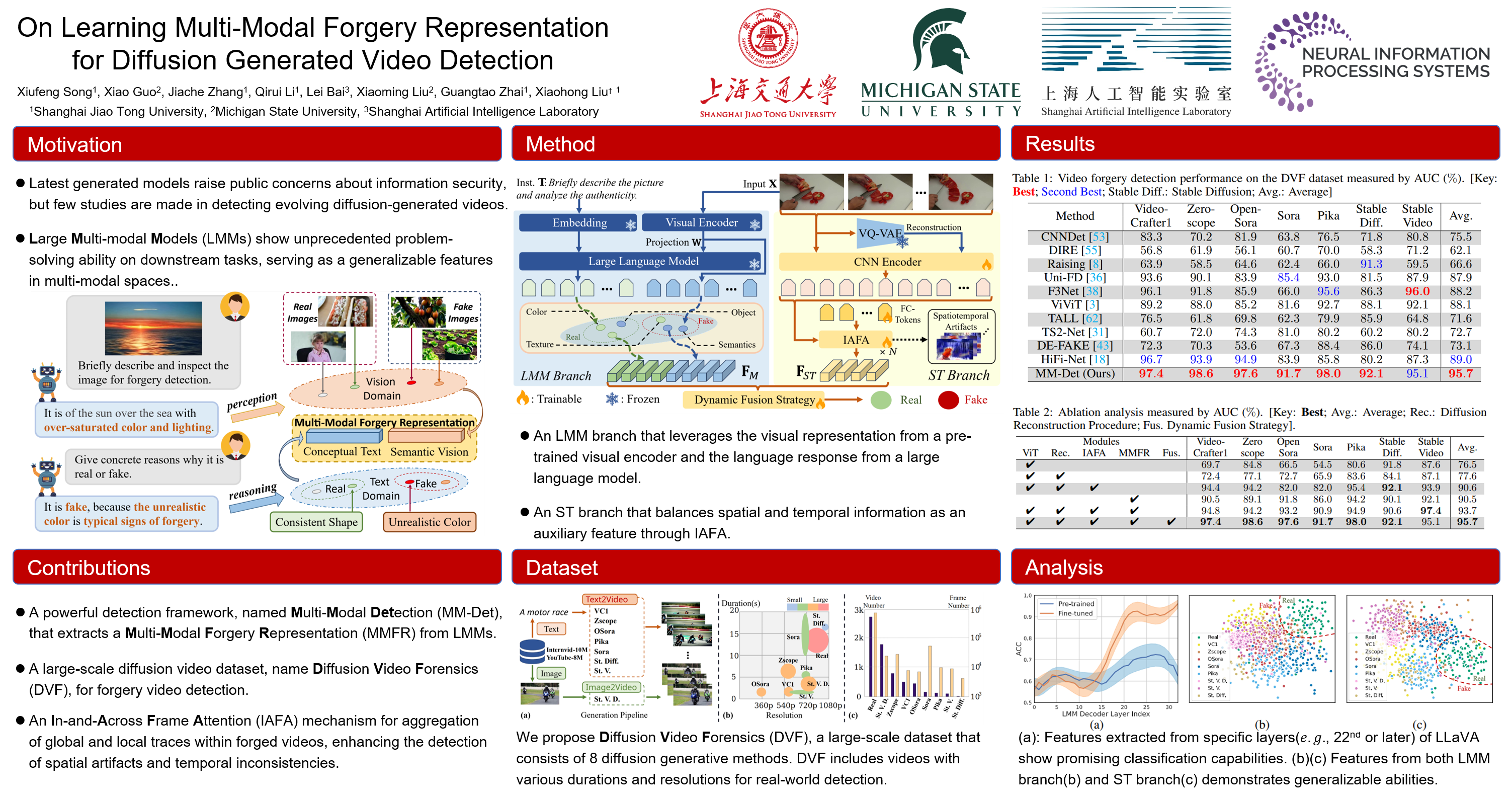
Large numbers of synthesized videos from diffusion models pose threats to information security and authenticity, leading to an increasing demand for generated content detection. However, existing video-level detection algorithms primarily focus on detecting facial forgeries and often fail to identify diffusion-generated content with a diverse range of semantics. To advance the field of video forensics, we propose an innovative algorithm named Multi-Modal Detection(MM-Det) for detecting diffusion-generated videos. MM-Det utilizes the profound perceptual and comprehensive abilities of Large Multi-modal Models (LMMs) by generating a Multi-Modal Forgery Representation (MMFR) from LMM's multi-modal space, enhancing its ability to detect unseen forgery content. Besides, MM-Det leverages an In-and-Across Frame Attention (IAFA) mechanism for feature augmentation in the spatio-temporal domain. A dynamic fusion strategy helps refine forgery representations for the fusion. Moreover, we construct a comprehensive diffusion video dataset, called Diffusion Video Forensics (DVF), across a wide range of forgery videos. MM-Det achieves state-of-the-art performance in DVF, demonstrating the effectiveness of our algorithm. Both source code and DVF are available at https://github.com/SparkleXFantasy/MM-Det.