Adaptive $Q$-Aid for Conditional Supervised Learning in Offline Reinforcement Learning
Jeonghye Kim ⋅ Suyoung Lee ⋅ Woojun Kim ⋅ Youngchul Sung
2024 Poster
{kind=link}
Abstract
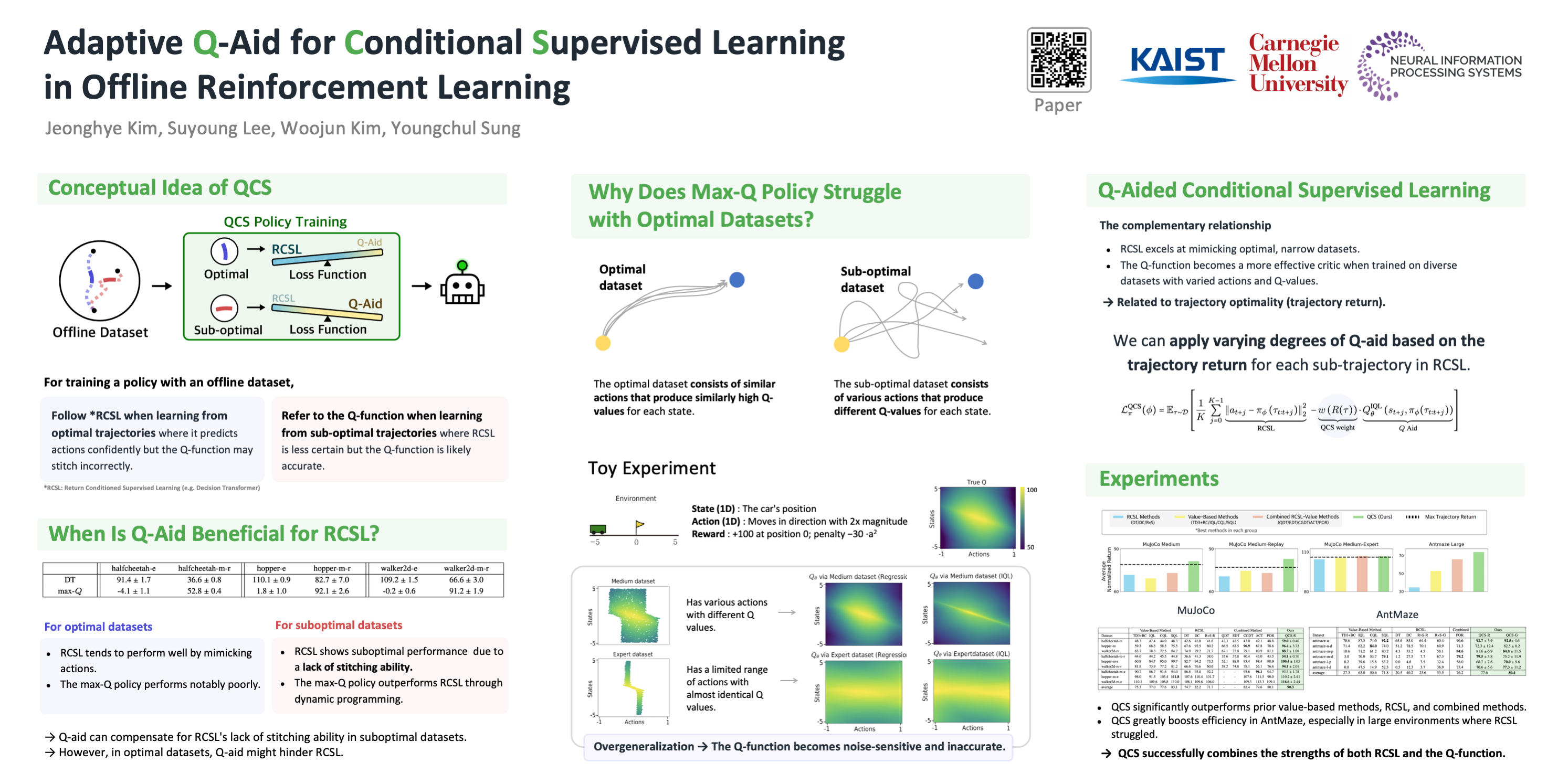
Offline reinforcement learning (RL) has progressed with return-conditioned supervised learning (RCSL), but its lack of stitching ability remains a limitation. We introduce $Q$-Aided Conditional Supervised Learning (QCS), which effectively combines the stability of RCSL with the stitching capability of $Q$-functions. By analyzing $Q$-function over-generalization, which impairs stable stitching, QCS adaptively integrates $Q$-aid into RCSL's loss function based on trajectory return. Empirical results show that QCS significantly outperforms RCSL and value-based methods, consistently achieving or exceeding the highest trajectory returns across diverse offline RL benchmarks. QCS represents a breakthrough in offline RL, pushing the limits of what can be achieved and fostering further innovations.
Video
Chat is not available.
Successful Page Load