Theoretical and Empirical Insights into the Origins of Degree Bias in Graph Neural Networks
{kind=link}
Abstract
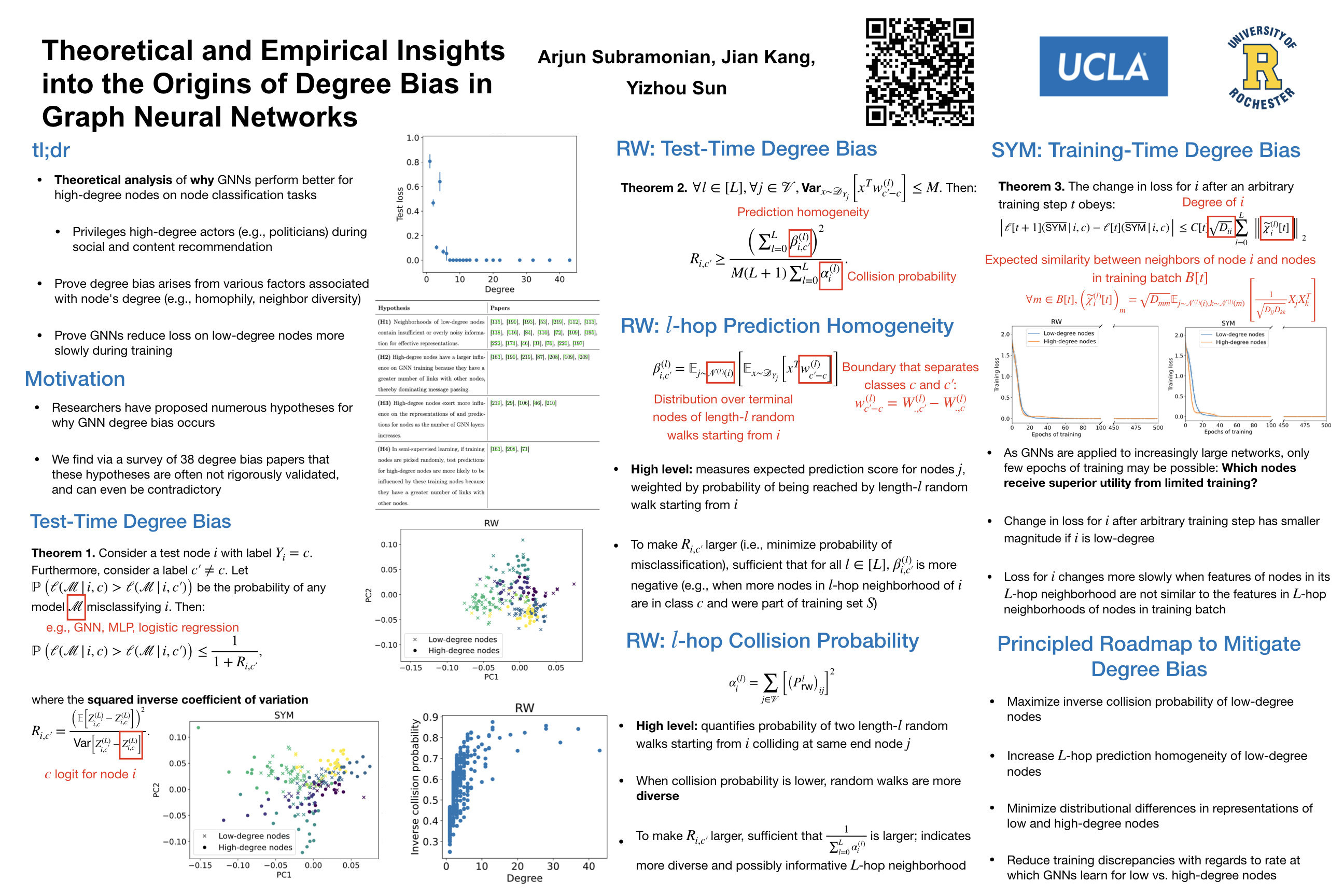
Graph Neural Networks (GNNs) often perform better for high-degree nodes than low-degree nodes on node classification tasks. This degree bias can reinforce social marginalization by, e.g., privileging celebrities and other high-degree actors in social networks during social and content recommendation. While researchers have proposed numerous hypotheses for why GNN degree bias occurs, we find via a survey of 38 degree bias papers that these hypotheses are often not rigorously validated, and can even be contradictory. Thus, we provide an analysis of the origins of degree bias in message-passing GNNs with different graph filters. We prove that high-degree test nodes tend to have a lower probability of misclassification regardless of how GNNs are trained. Moreover, we show that degree bias arises from a variety of factors that are associated with a node's degree (e.g., homophily of neighbors, diversity of neighbors). Furthermore, we show that during training, some GNNs may adjust their loss on low-degree nodes more slowly than on high-degree nodes; however, with sufficiently many epochs of training, message-passing GNNs can achieve their maximum possible training accuracy, which is not significantly limited by their expressive power. Throughout our analysis, we connect our findings to previously-proposed hypotheses for the origins of degree bias, supporting and unifying some while drawing doubt to others. We validate our theoretical findings on 8 common real-world networks, and based on our theoretical and empirical insights, describe a roadmap to alleviate degree bias.