Toggle Poster Visibility
Fri Dec 02 06:20 AM -- 06:30 AM (PST) None
Opening Remarks
Fri Dec 02 06:30 AM -- 07:00 AM (PST) None
Offline RL in the context of "Collect and Infer" (Martin Riedmiller)
Fri Dec 02 07:00 AM -- 07:10 AM (PST) None
Efficient Planning in a Compact Latent Action Space
Fri Dec 02 07:10 AM -- 07:20 AM (PST) None
Control Graph as Unified IO for Morphology-Task Generalization
Fri Dec 02 07:20 AM -- 07:30 AM (PST) None
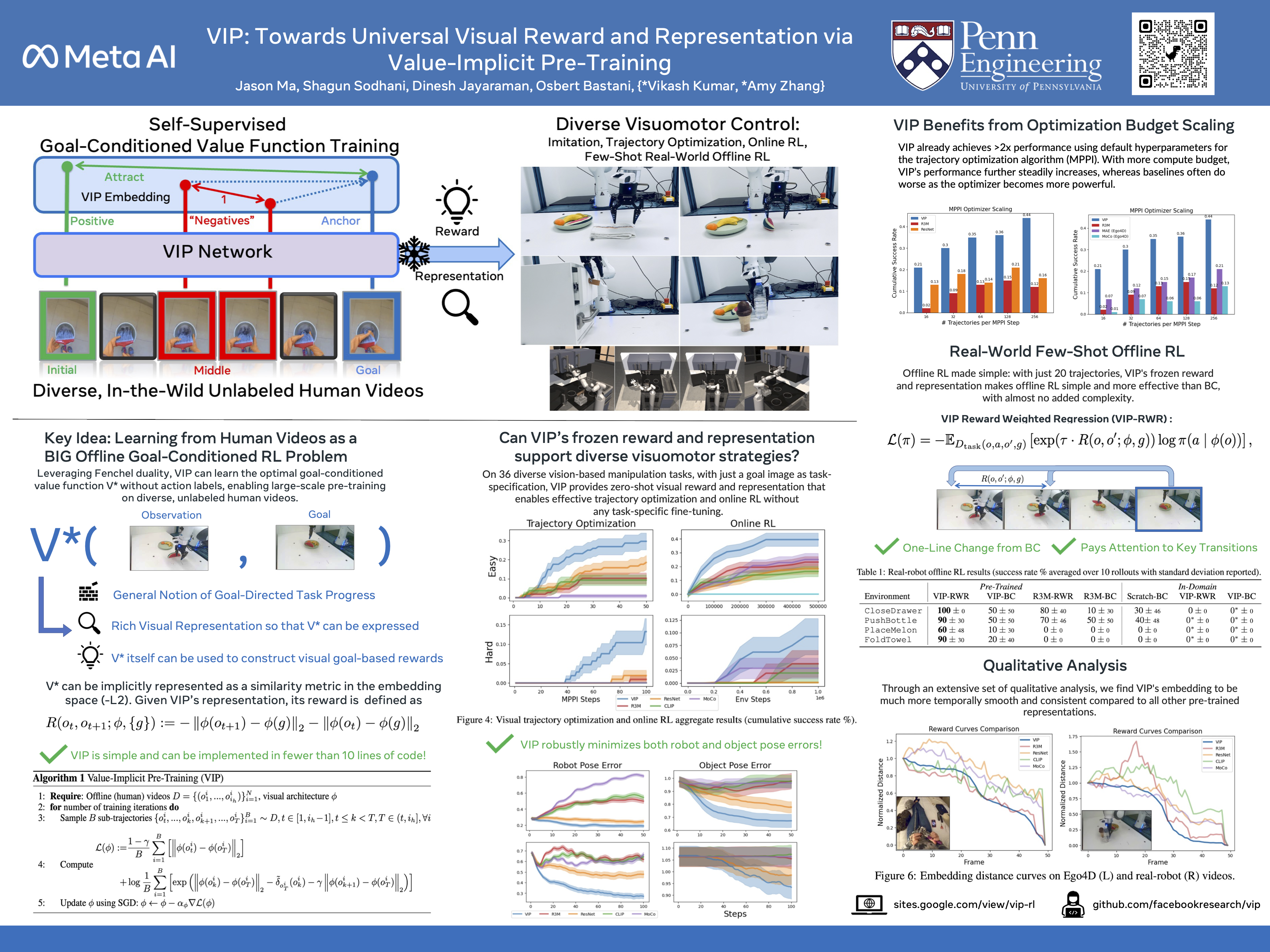
Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Fri Dec 02 07:35 AM -- 08:05 AM (PST) None
AV2.0: Learning to Drive at a Global Scale (Alex Kendall)
Fri Dec 02 08:05 AM -- 09:10 AM (PST) None
Poster Session 1
Fri Dec 02 09:10 AM -- 09:40 AM (PST) None
Learning from Suboptimal Demonstrations with No Rewards (Dorsa Sadigh)
Fri Dec 02 09:40 AM -- 10:30 AM (PST) None
Break
Fri Dec 02 10:45 AM -- 11:30 AM (PST) None
Panel Discussion 1 - Applications
Fri Dec 02 11:30 AM -- 11:40 AM (PST) None
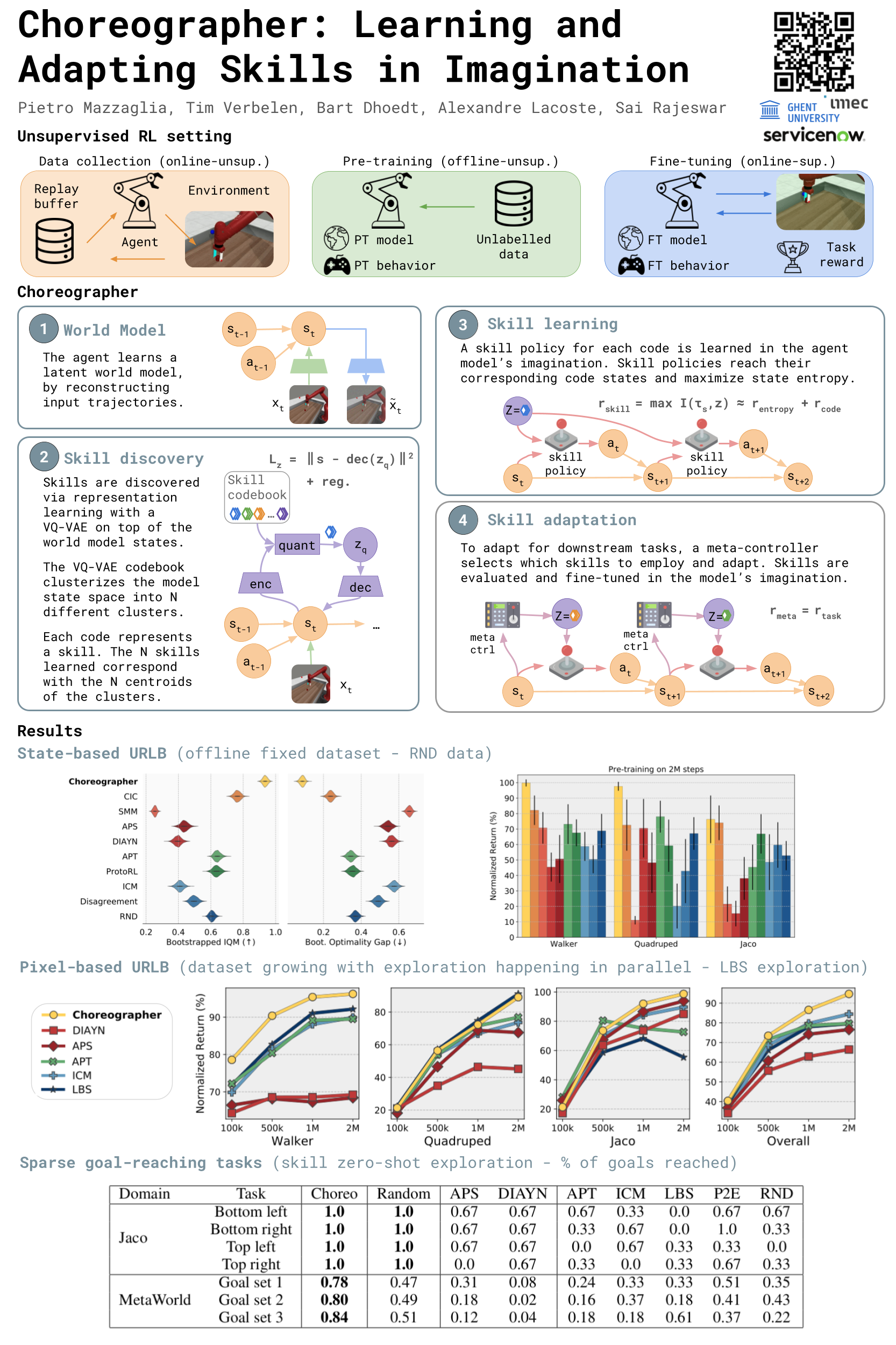
Choreographer: Learning and Adapting Skills in Imagination
Fri Dec 02 11:40 AM -- 11:50 AM (PST) None
Provable Benefits of Representational Transfer in Reinforcement Learning
Fri Dec 02 11:50 AM -- 12:00 PM (PST) None
Pareto-Efficient Decision Agents for Offline Multi-Objective Reinforcement Learning
Fri Dec 02 12:00 PM -- 01:00 PM (PST) None
Poster Session 2
Fri Dec 02 01:00 PM -- 01:30 PM (PST) None
Reinforcement Learning and LTV at Spotify (Tony Jebara)
Fri Dec 02 01:30 PM -- 02:00 PM (PST) None
Hybrid RL: Using Both Offline and Online Data Can Make RL Efficient (Wen Sun)
Fri Dec 02 02:00 PM -- 03:00 PM (PST) None
Panel Discussion 2 - Research
Fri Dec 02 03:00 PM -- 03:30 PM (PST) None
Identification of Dead-ends in Safety-Critical Offline RL (Talyor Killian)
{kind=link}
{kind=link}
None
Visual Backtracking Teleoperation: A Data Collection Protocol for Offline Image-Based RL
[
Poster]
[
OpenReview]
{kind=link}
None
Squeezing more value out of your historical data: data-augmented behavioural cloning as launchpad for reinforcement learning
[
Poster]
[
OpenReview]
{kind=link}
None
Keep Calm and Carry Offline: Policy refinement in offline reinforcement learning
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
None
Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
{kind=link}
None
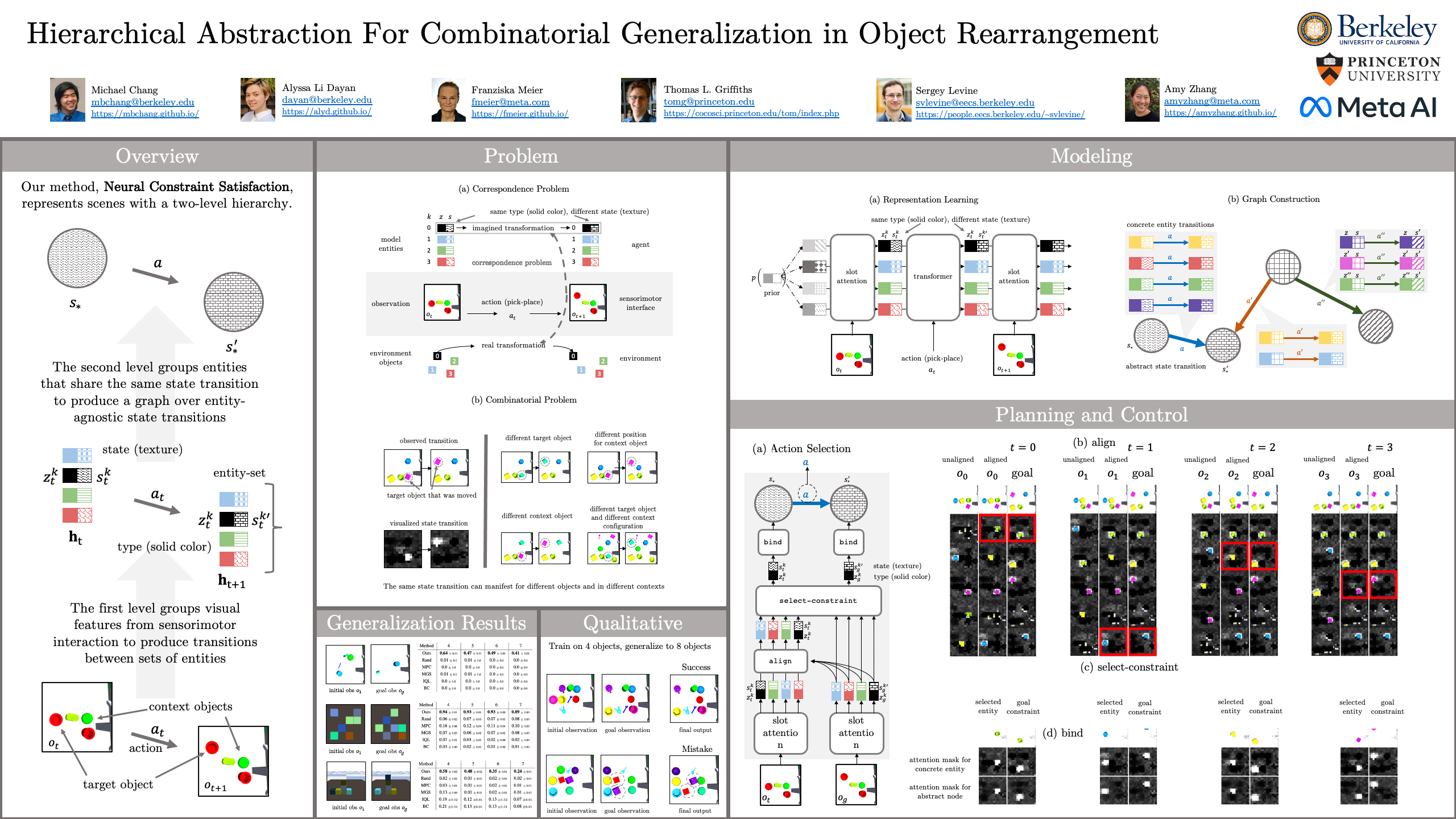
Hierarchical Abstraction for Combinatorial Generalization in Object Rearrangement
[
Poster]
[
OpenReview]
{kind=link}
None
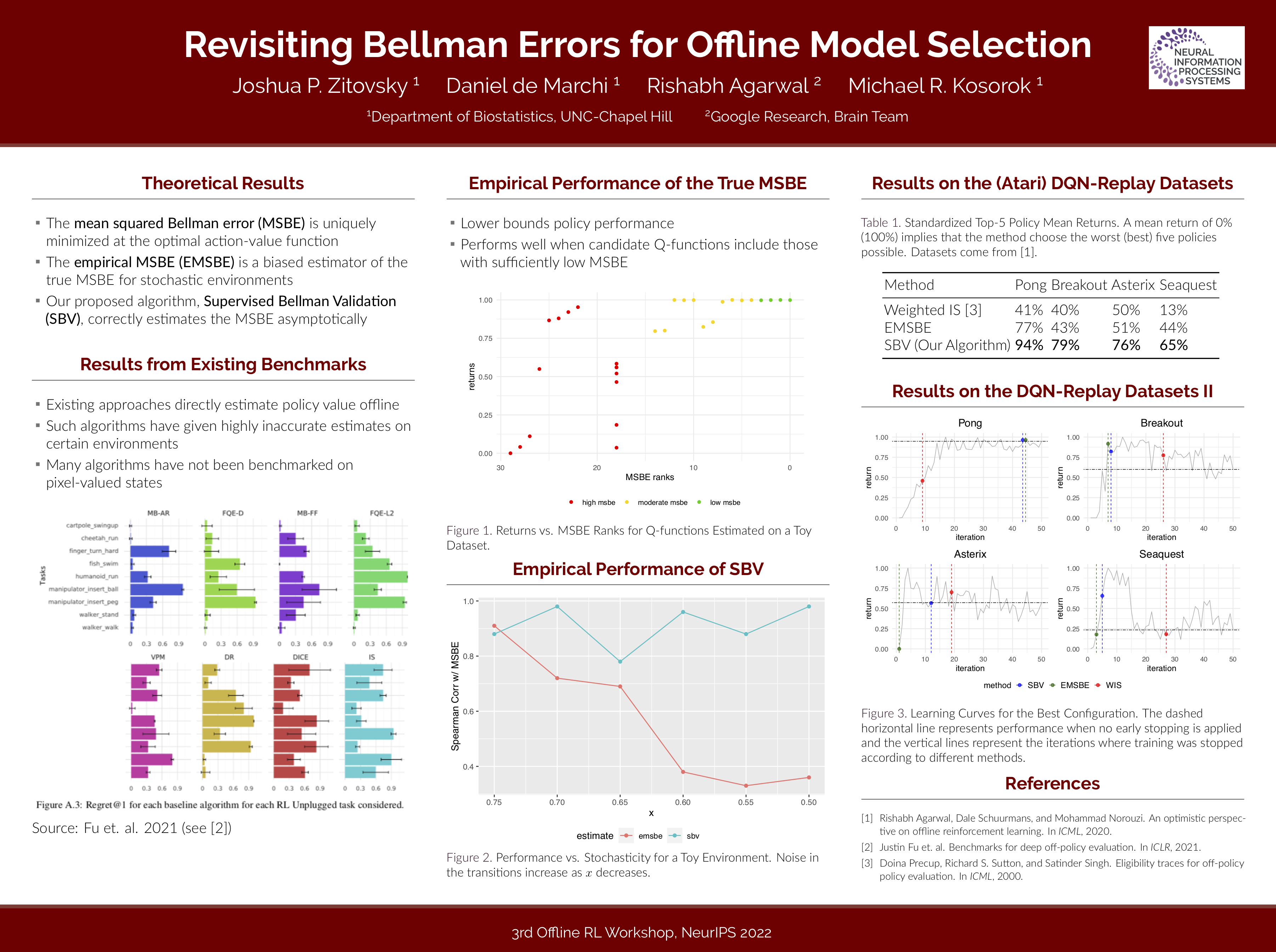
Efficient Deep Reinforcement Learning Requires Regulating Statistical Overfitting
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
None
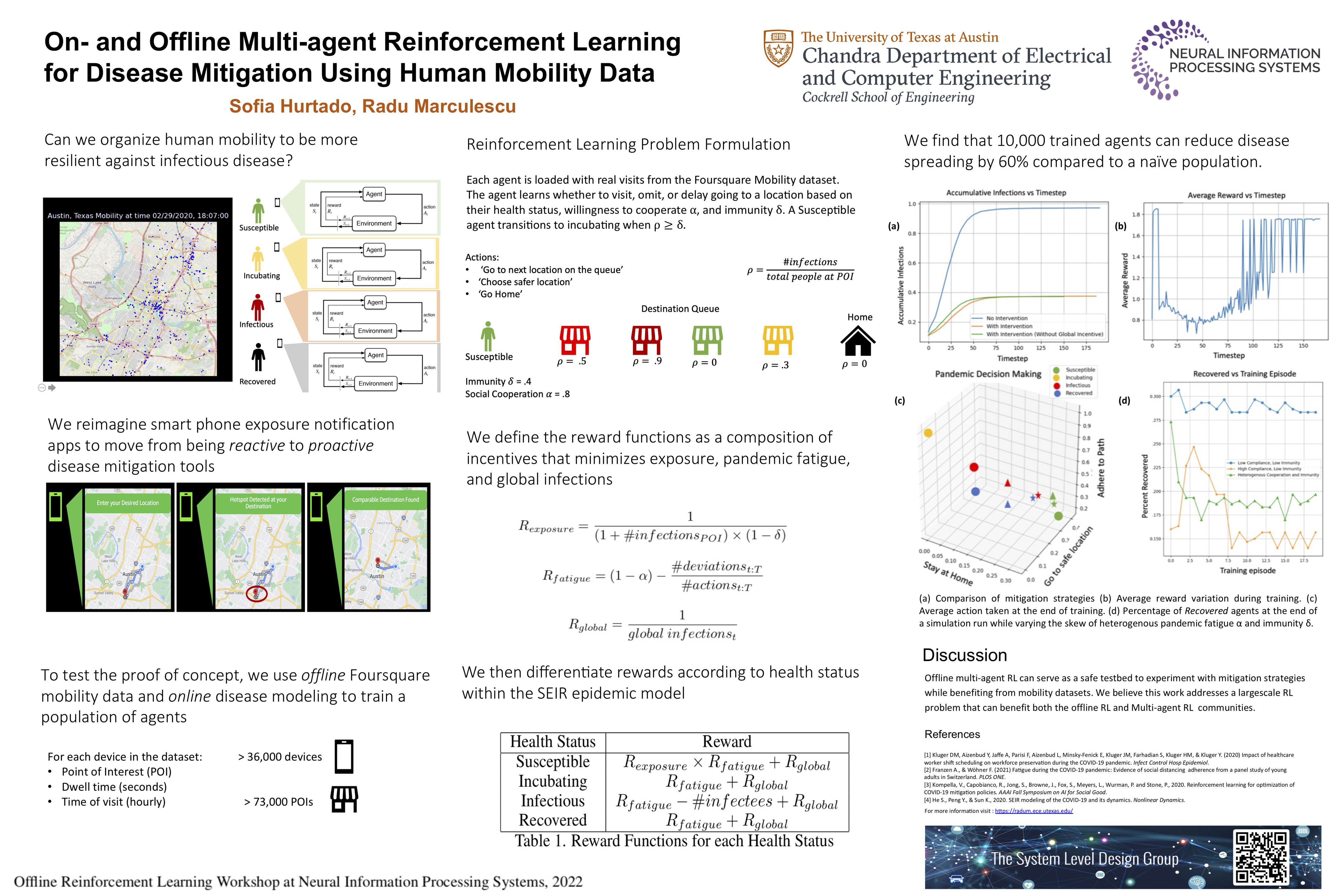
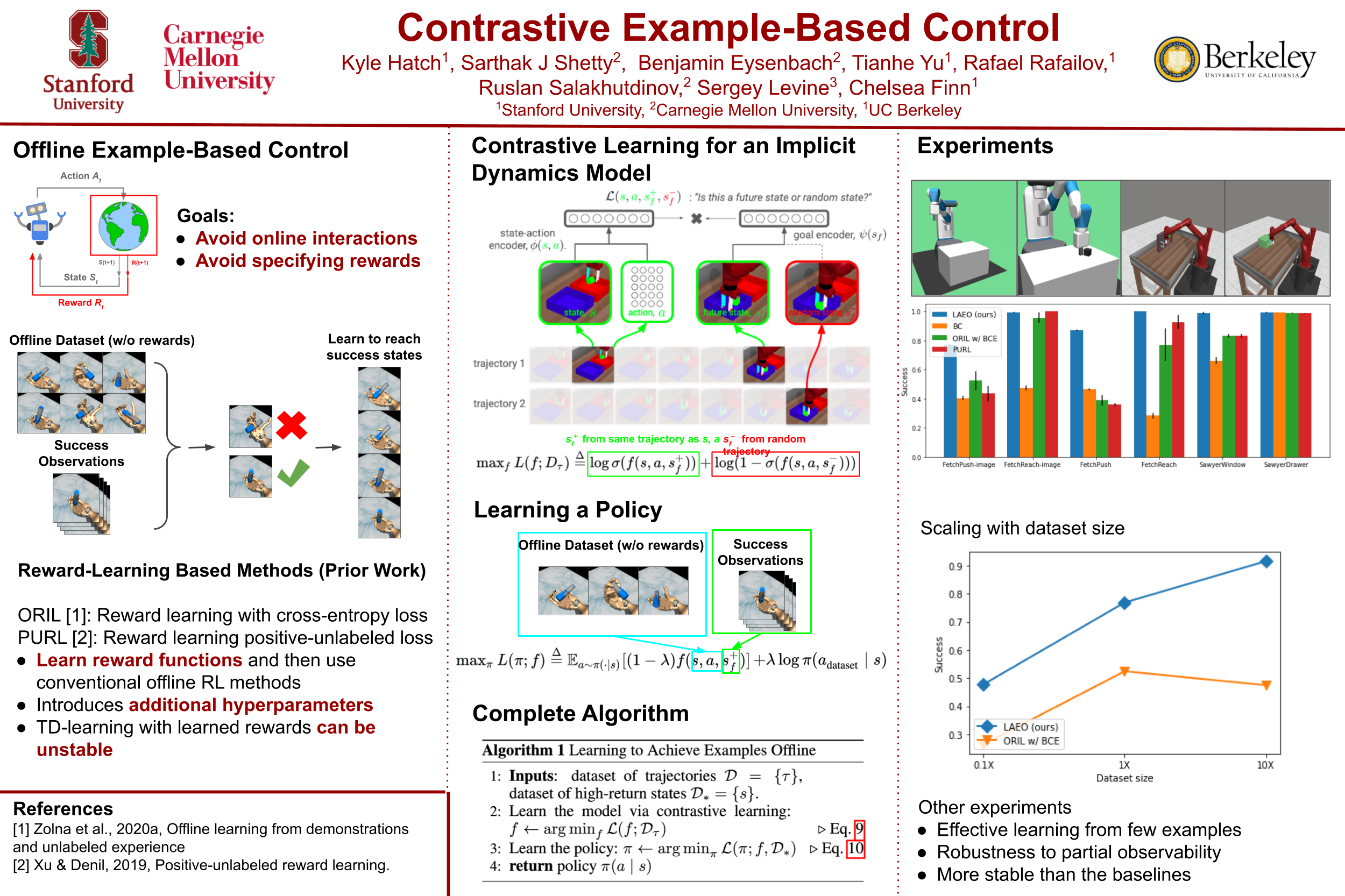
On- and Offline Multi-agent Reinforcement Learning for Disease Mitigation using Human Mobility Data
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
None
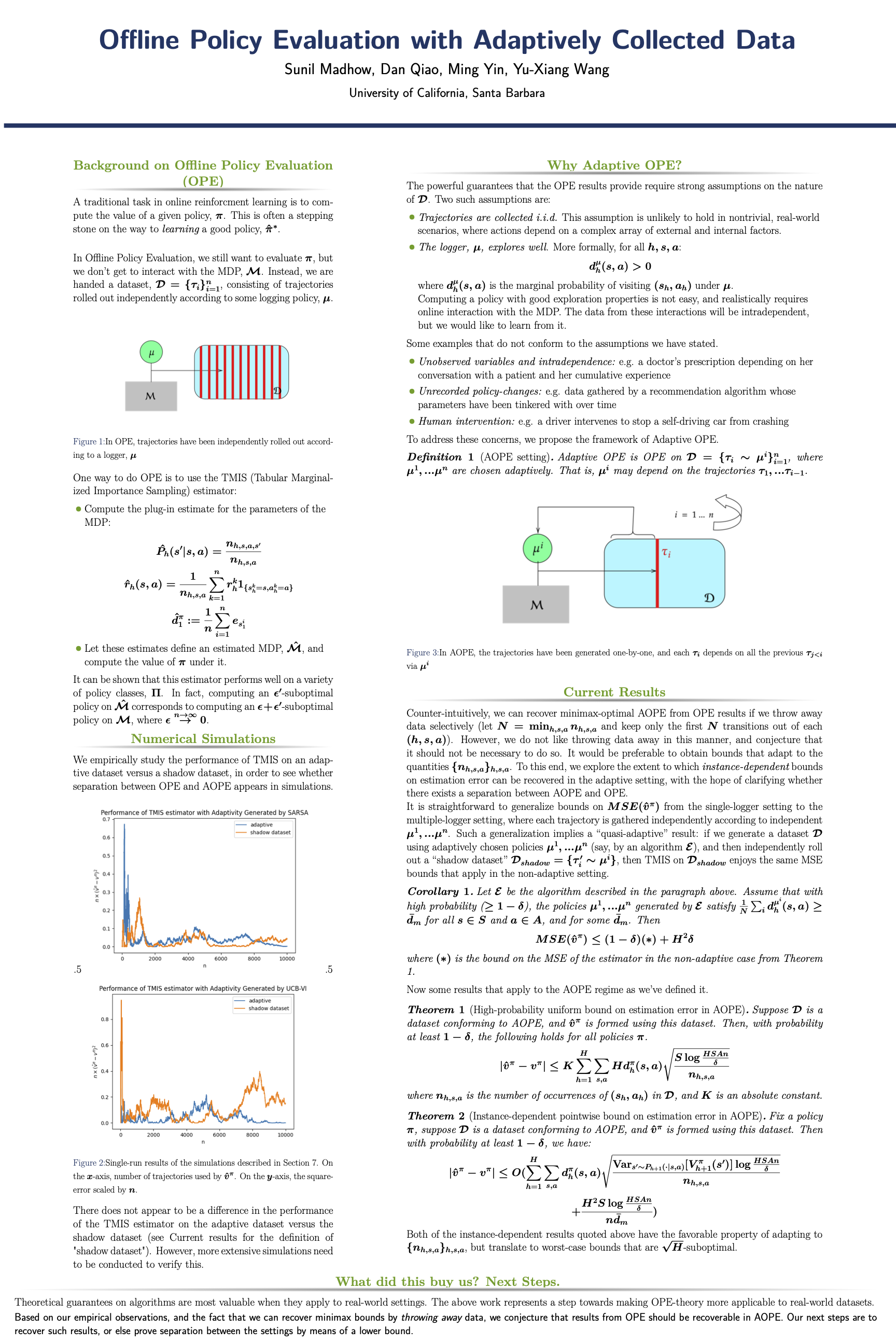
Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
[
Poster]
[
OpenReview]
{kind=link}
None
Collaborative symmetricity exploitation for offline learning of hardware design solver
[
Poster]
[
OpenReview]
{kind=link}
None
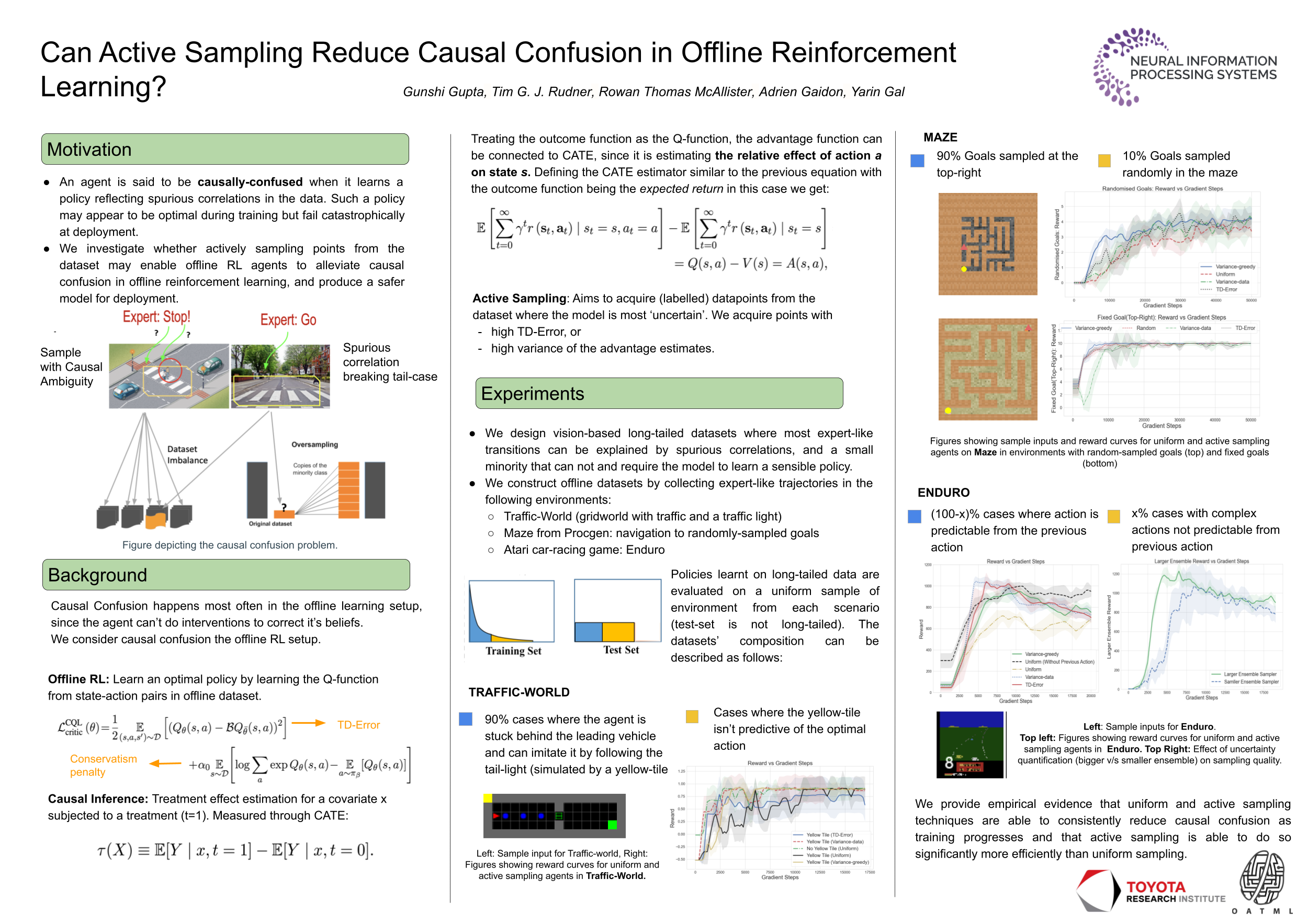
Can Active Sampling Reduce Causal Confusion in Offline Reinforcement Learning?
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
None
ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning
[
Poster]
[
OpenReview]
{kind=link}
None
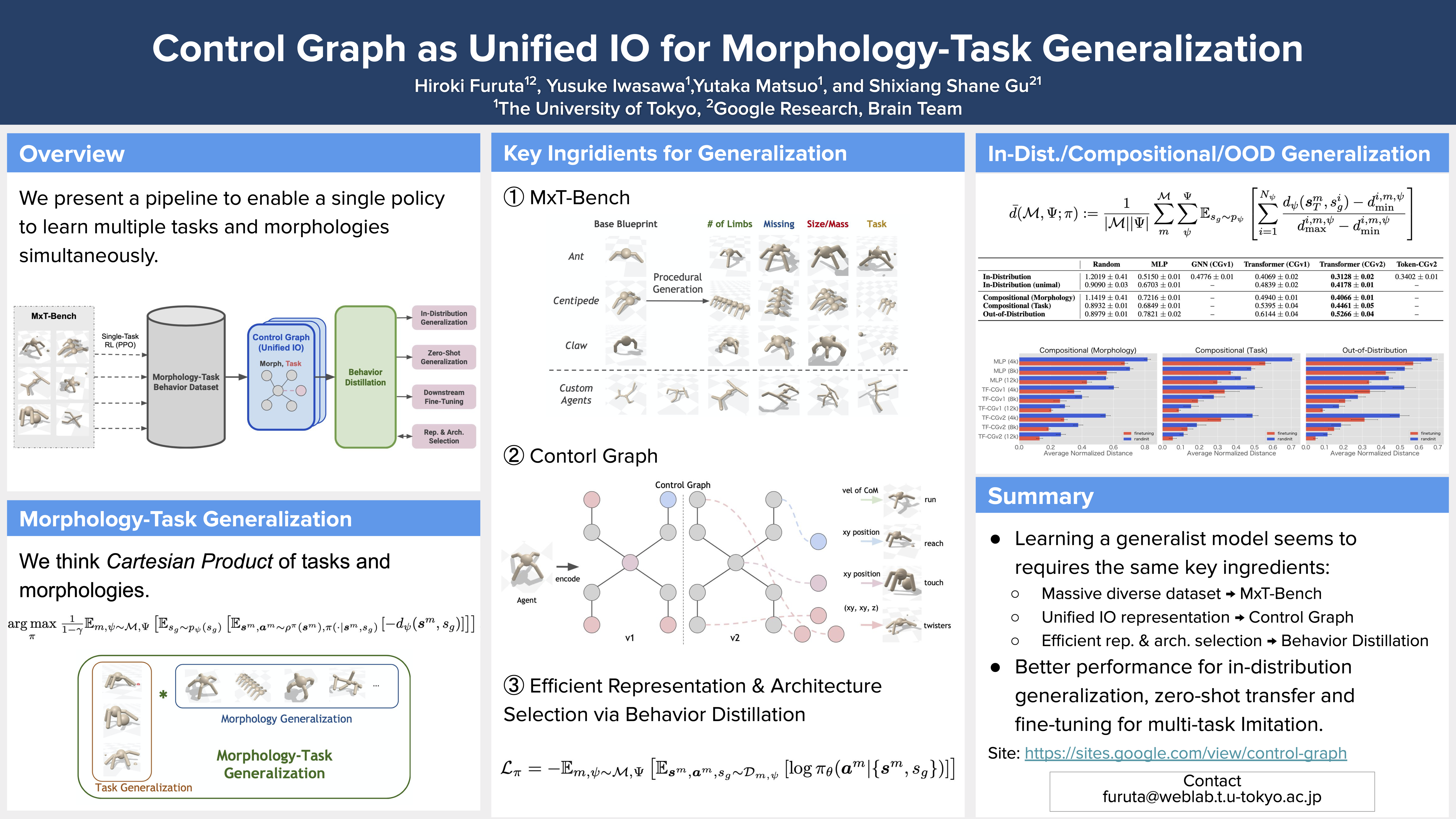
Dynamics-Augmented Decision Transformer for Offline Dynamics Generalization
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
None
Uncertainty-Driven Pessimistic Q-Ensemble for Offline-to-Online Reinforcement Learning
[
Poster]
[
OpenReview]
{kind=link}
None
Offline Robot Reinforcement Learning with Uncertainty-Guided Human Expert Sampling
[
Poster]
[
OpenReview]
{kind=link}
None
Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
None
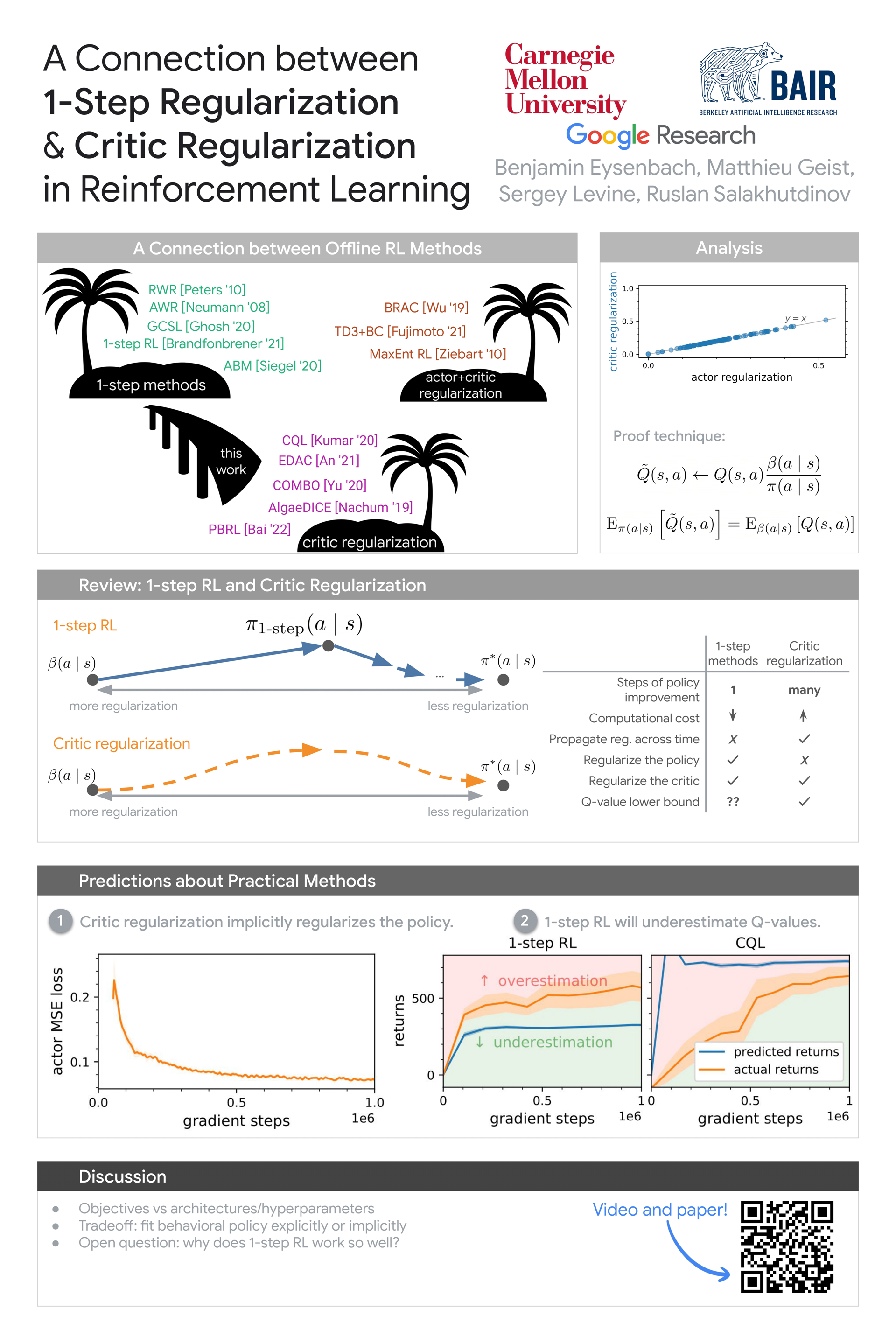
A Connection between One-Step Regularization and Critic Regularization in Reinforcement Learning
[
Poster]
[
OpenReview]
{kind=link}
None
Offline evaluation in RL: soft stability weighting to combine fitted Q-learning and model-based methods
[
OpenReview]
{kind=link}
None
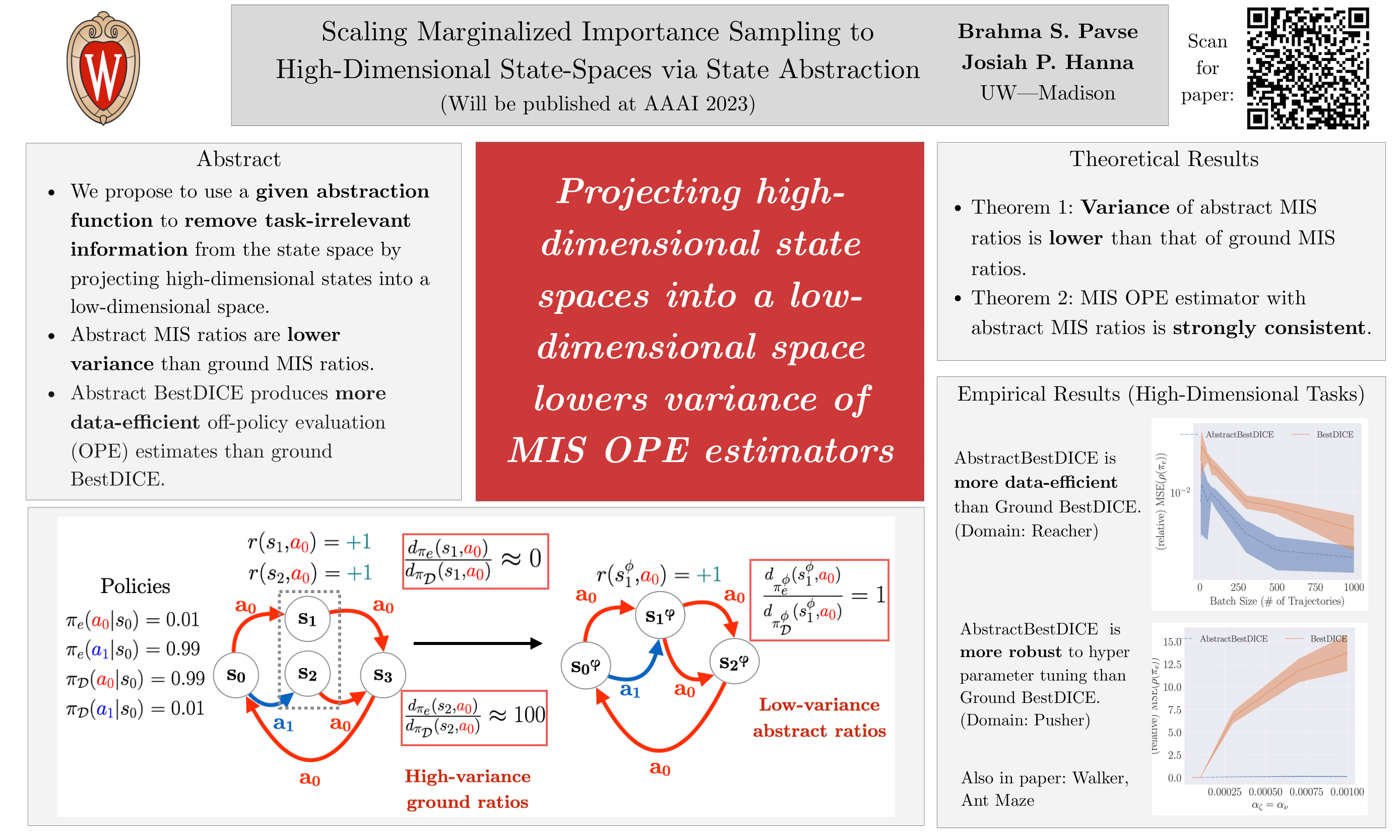
Scaling Marginalized Importance Sampling to High-Dimensional State-Spaces via State Abstraction
[
Poster]
[
OpenReview]
{kind=link}
None
Benchmarking Offline Reinforcement Learning Algorithms for E-Commerce Order Fraud Evaluation
[
Poster]
[
OpenReview]
{kind=link}
None
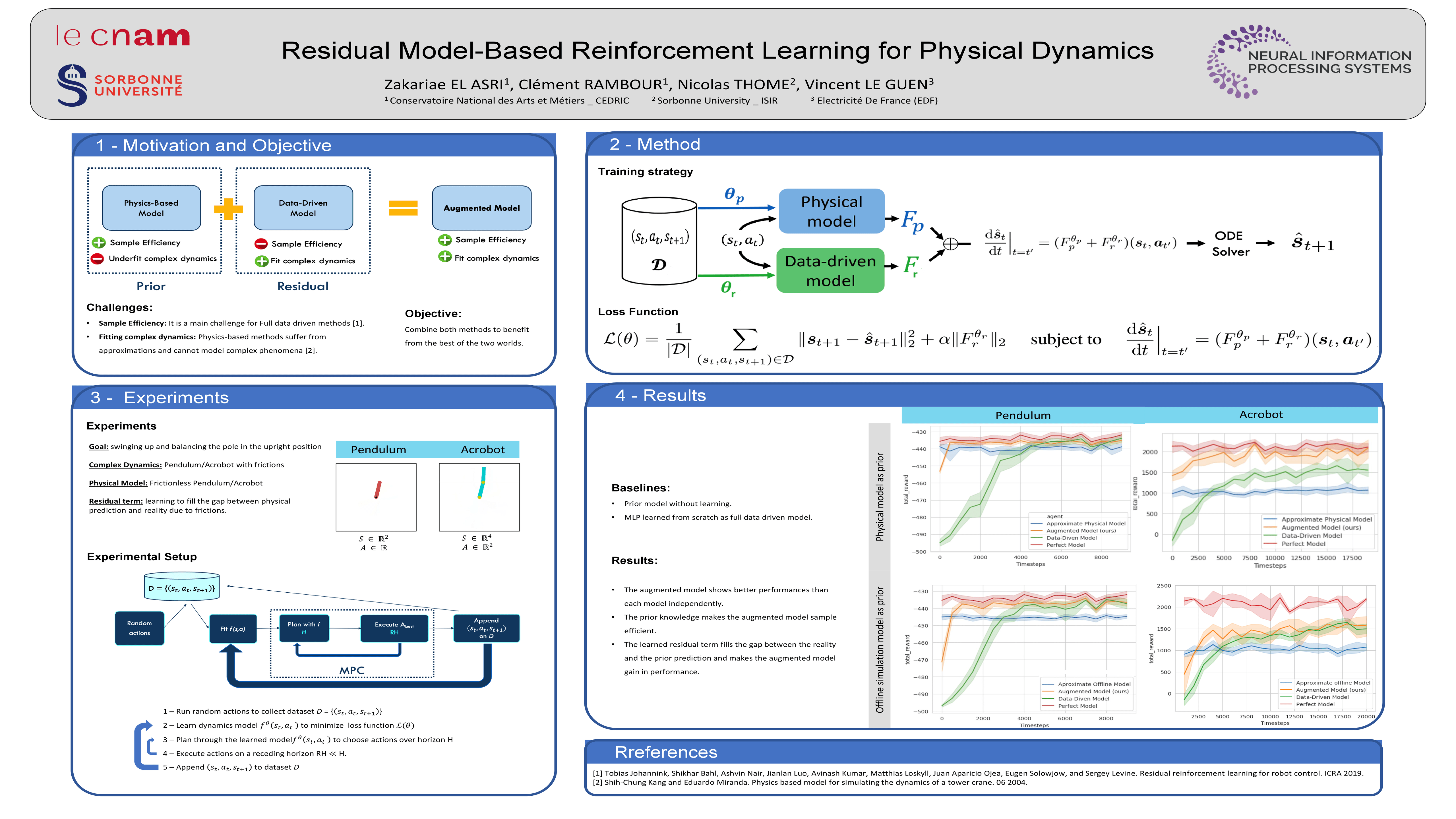
Sparse Q-Learning: Offline Reinforcement Learning with Implicit Value Regularization
[
OpenReview]
{kind=link}
None
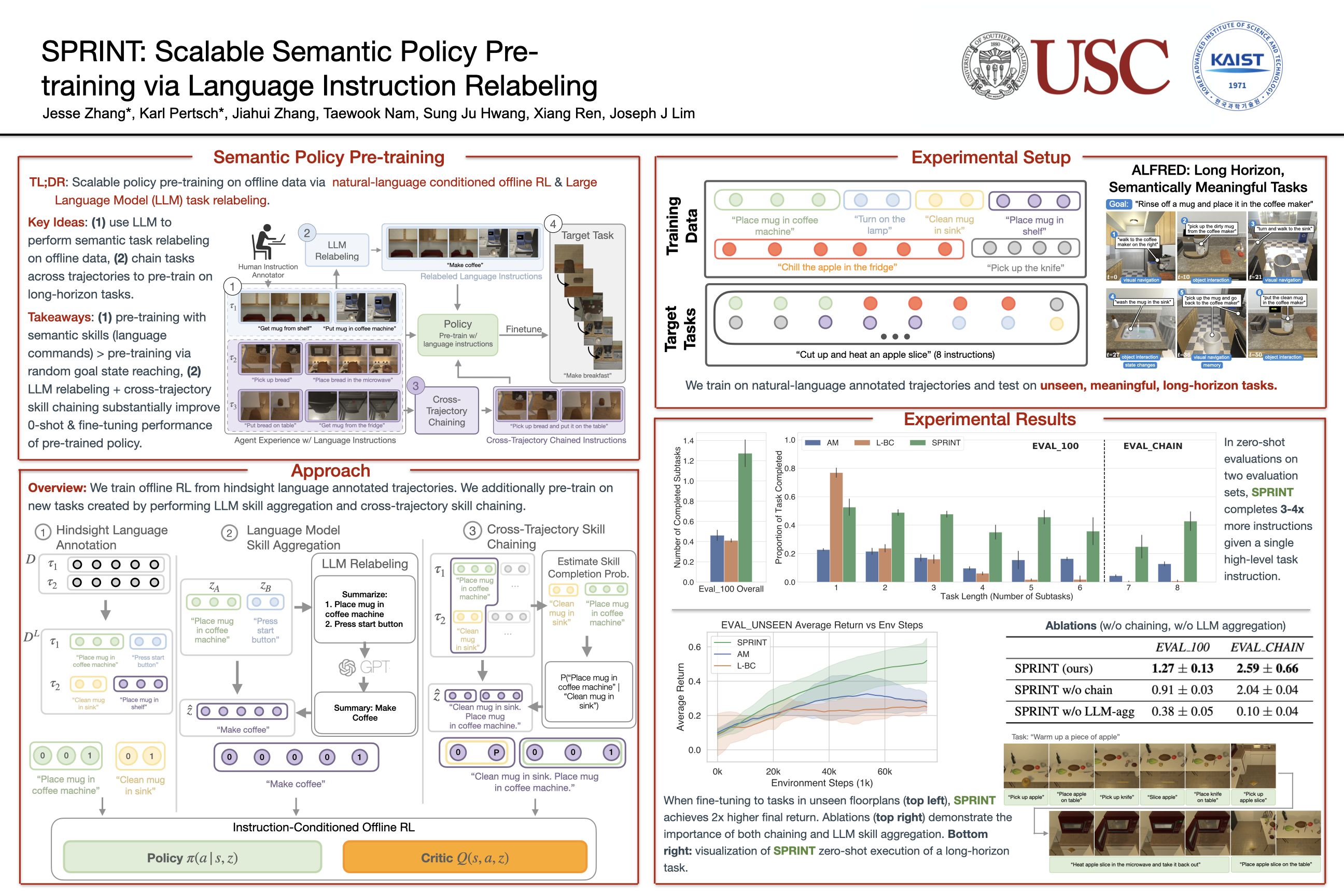
SPRINT: Scalable Semantic Policy Pre-training via Language Instruction Relabeling
[
Poster]
[
OpenReview]
{kind=link}
None
Offline Reinforcement Learning on Real Robot with Realistic Data Sources
[
Poster]
[
OpenReview]
{kind=link}
None
Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information
[
OpenReview]
None
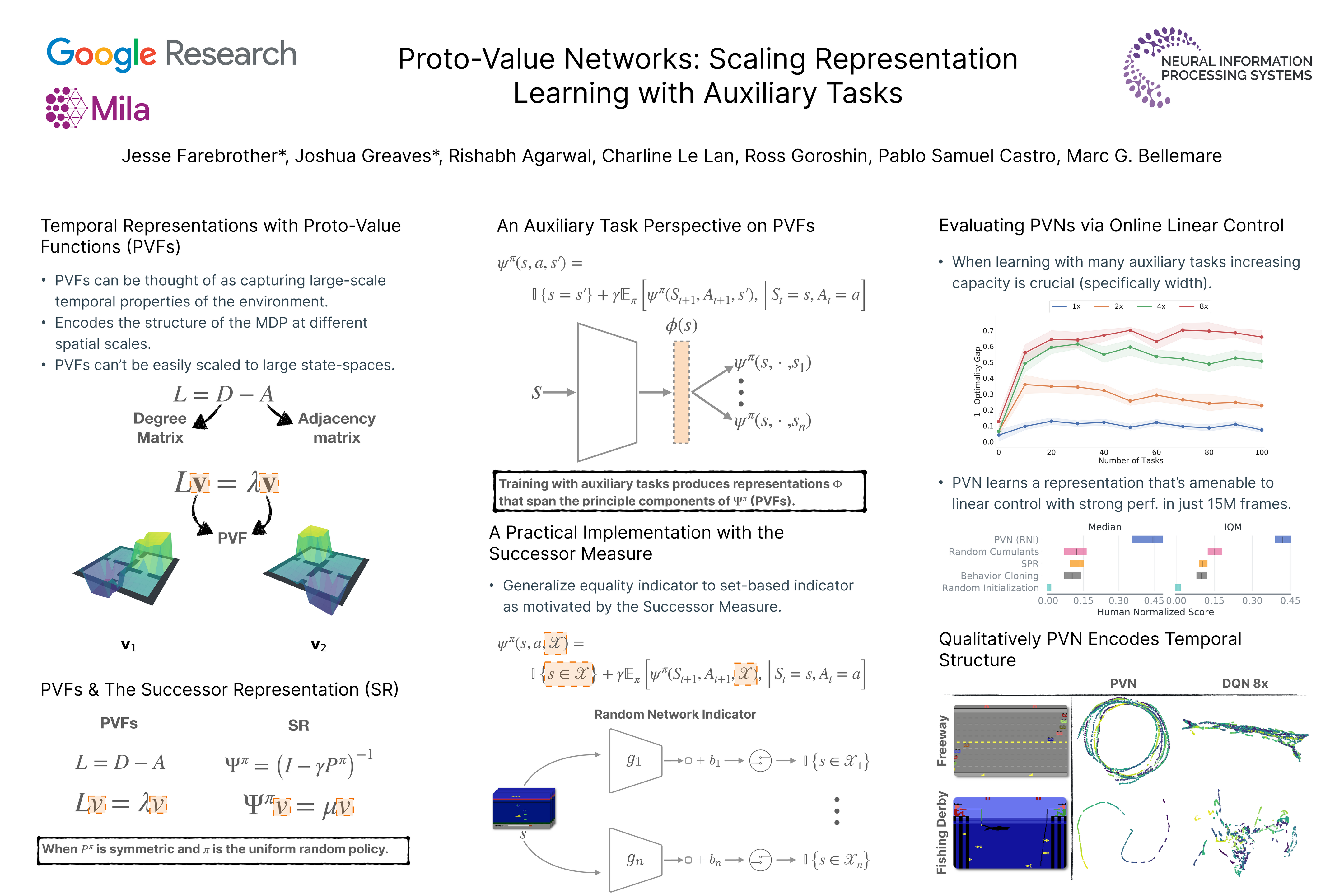
Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks
[
Poster]
[
OpenReview]
{kind=link}
{kind=link}
None
Matrix Estimation for Offline Evaluation in Reinforcement Learning with Low-Rank Structure
[
Poster]
[
OpenReview]
{kind=link}
None
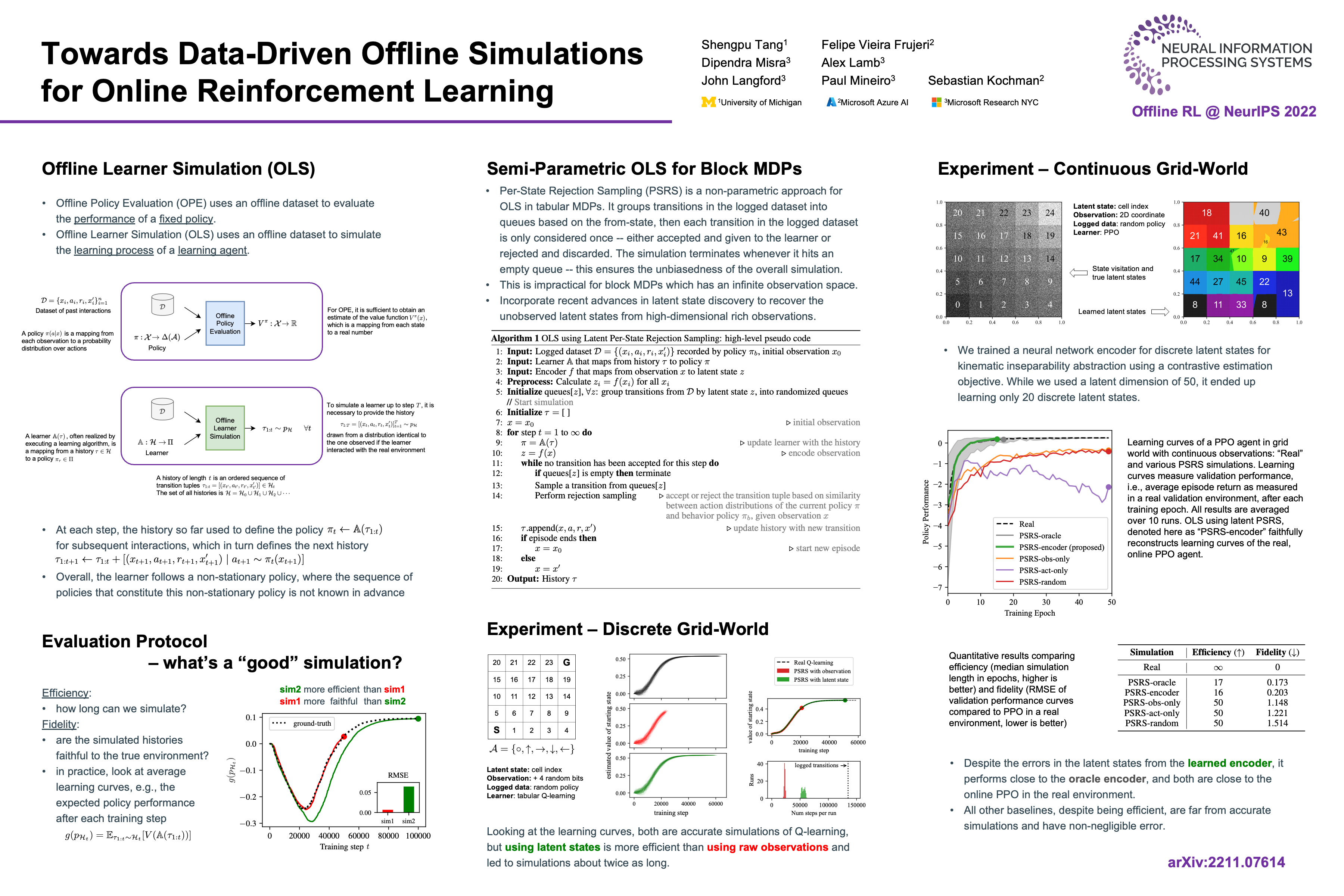
Towards Data-Driven Offline Simulations for Online Reinforcement Learning
[
Poster]
[
OpenReview]
{kind=link}
None
Let Offline RL Flow: Training Conservative Agents in the Latent Space of Normalizing Flows
[
OpenReview]
None
Bridging the Gap Between Offline and Online Reinforcement Learning Evaluation Methodologies
[
Poster]
[
OpenReview]
{kind=link}
None
Pareto-Efficient Decision Agents for Offline Multi-Objective Reinforcement Learning
[
OpenReview]
None
Offline Reinforcement Learning with Closed-Form Policy Improvement Operators
[
Poster]
[
OpenReview]
{kind=link}
None
AMORE: A Model-based Framework for Improving Arbitrary Baseline Policies with Offline Data
[
OpenReview]
None
General policy mapping: online continual reinforcement learning inspired on the insect brain
[
Poster]
[
OpenReview]
{kind=link}
Successful Page Load