Toggle Poster Visibility
Fri Dec 02 06:15 AM -- 06:30 AM (PST) None
Welcome and Opening Remarks
Fri Dec 02 06:30 AM -- 07:15 AM (PST) None
Efficient Second-Order Stochastic Methods for Machine Learning
Fri Dec 02 07:15 AM -- 08:00 AM (PST) None
Tensor Methods for Nonconvex Optimization.
Fri Dec 02 08:00 AM -- 08:30 AM (PST) None
Coffee Break
Fri Dec 02 08:00 AM -- 08:30 AM (PST) None
Poster Session I
Fri Dec 02 08:30 AM -- 08:45 AM (PST) None
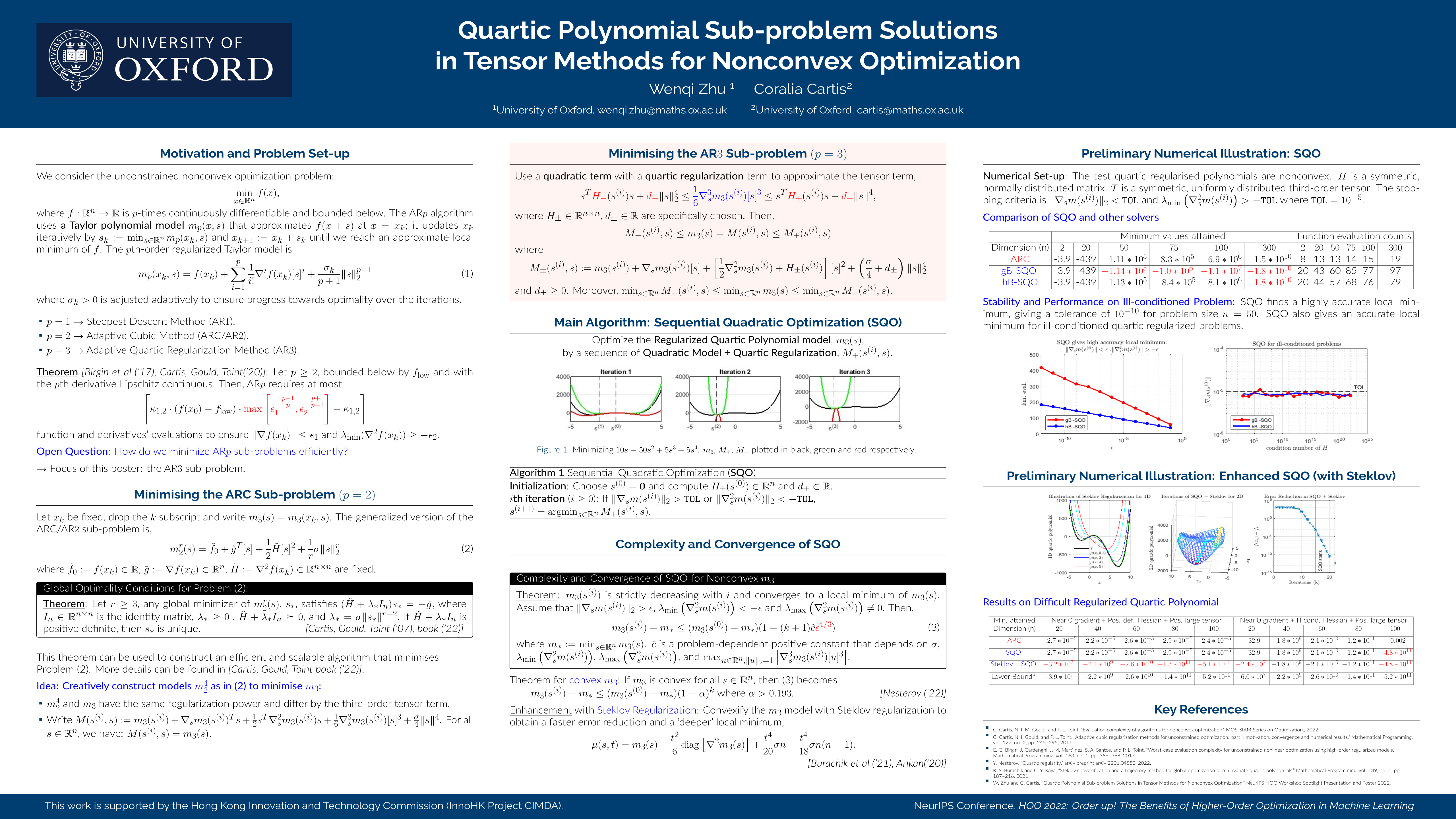
Quartic Polynomial Sub-problem Solutions in Tensor Methods for Nonconvex Optimization
Fri Dec 02 08:45 AM -- 09:00 AM (PST) None
PSPS: Preconditioned Stochastic Polyak Step-size method for badly scaled data
Fri Dec 02 09:00 AM -- 09:15 AM (PST) None
DRSOM: A Dimension Reduced Second-Order Method
Fri Dec 02 09:15 AM -- 09:30 AM (PST) None
Disentangling the Mechanisms Behind Implicit Regularization in SGD
Fri Dec 02 09:30 AM -- 09:45 AM (PST) None
Cubic Regularized Quasi-Newton Methods
Fri Dec 02 09:45 AM -- 10:00 AM (PST) None
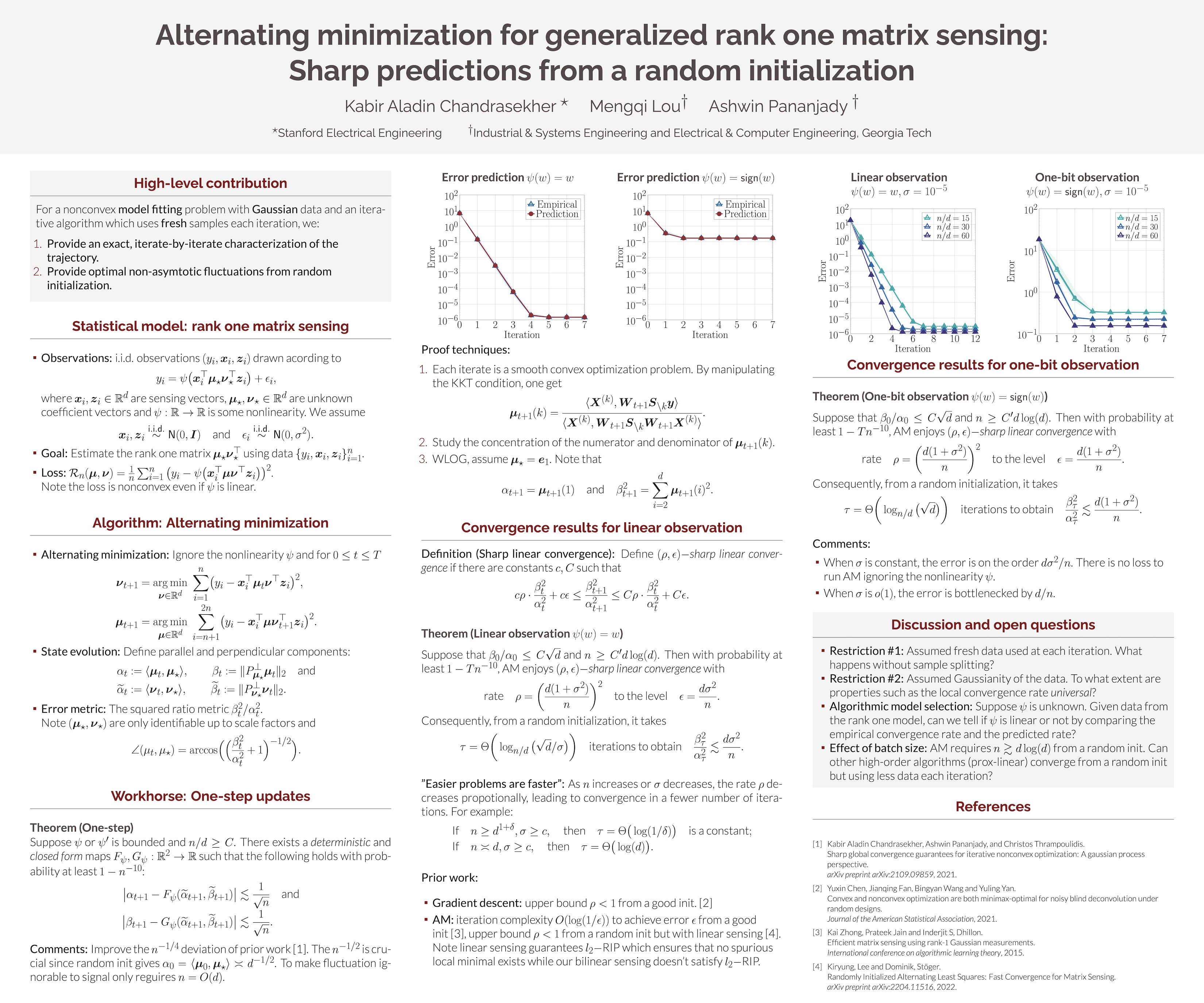
Alternating minimization for generalized rank one matrix sensing: Sharp predictions from a random initialization
Fri Dec 02 10:00 AM -- 11:30 AM (PST) None
Lunch Break
Fri Dec 02 11:30 AM -- 12:15 PM (PST) None
Deterministically Constrained Stochastic Optimization
Fri Dec 02 12:15 PM -- 01:00 PM (PST) None
Low Rank Approximation for Faster Convex Optimization
Fri Dec 02 01:00 PM -- 01:30 PM (PST) None
Coffee Break
Fri Dec 02 01:00 PM -- 02:00 PM (PST) None
Poster Session II
Fri Dec 02 02:00 PM -- 02:45 PM (PST) None
A Fast, Fisher Based Pruning of Transformers without Retraining
Fri Dec 02 02:45 PM -- 03:00 PM (PST) None
Closing Remarks
{kind=link}
None
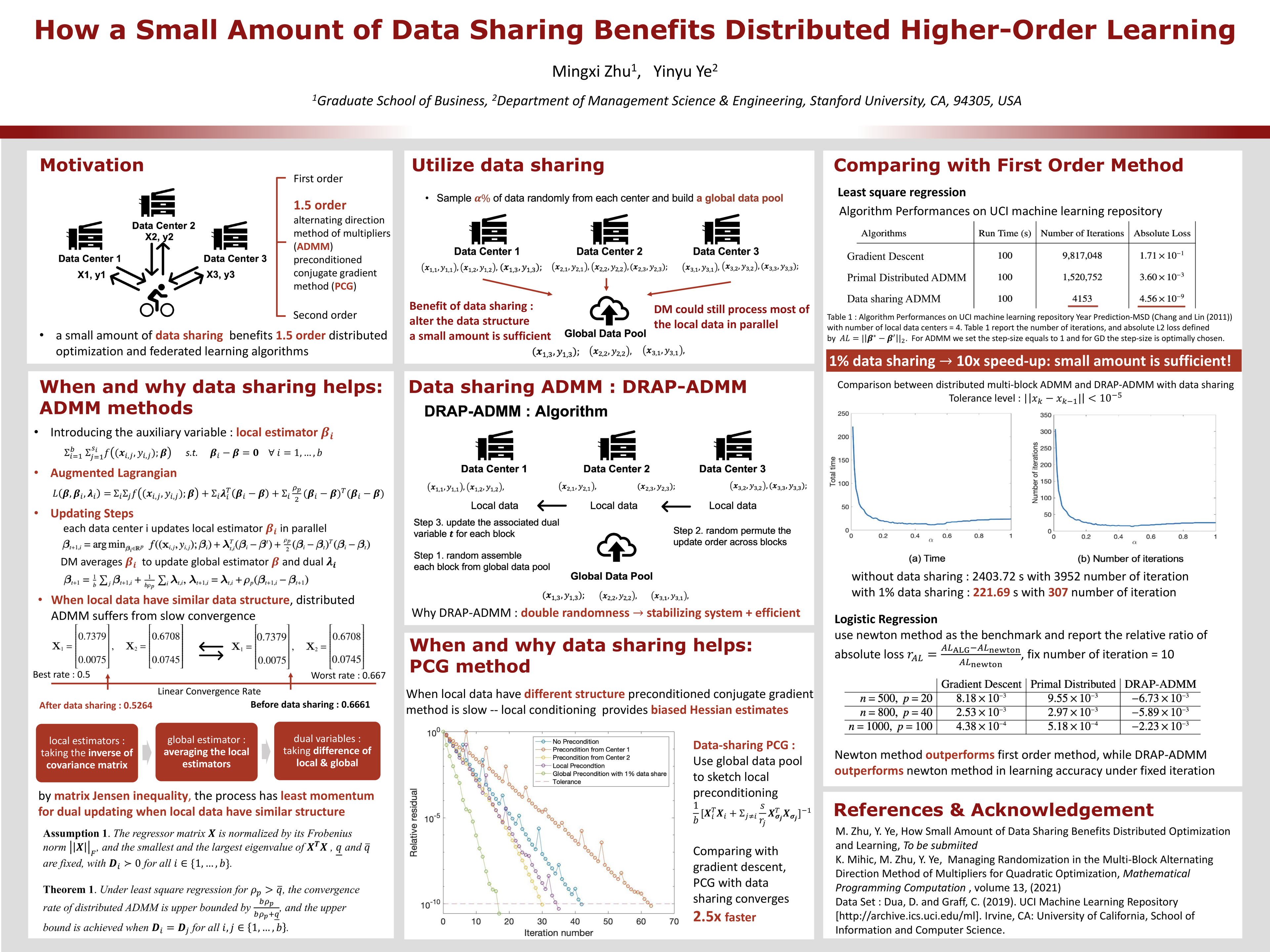
How Small Amount of Data Sharing Benefits Higher-Order Distributed Optimization and Learning
[
Poster]
{kind=link}
None
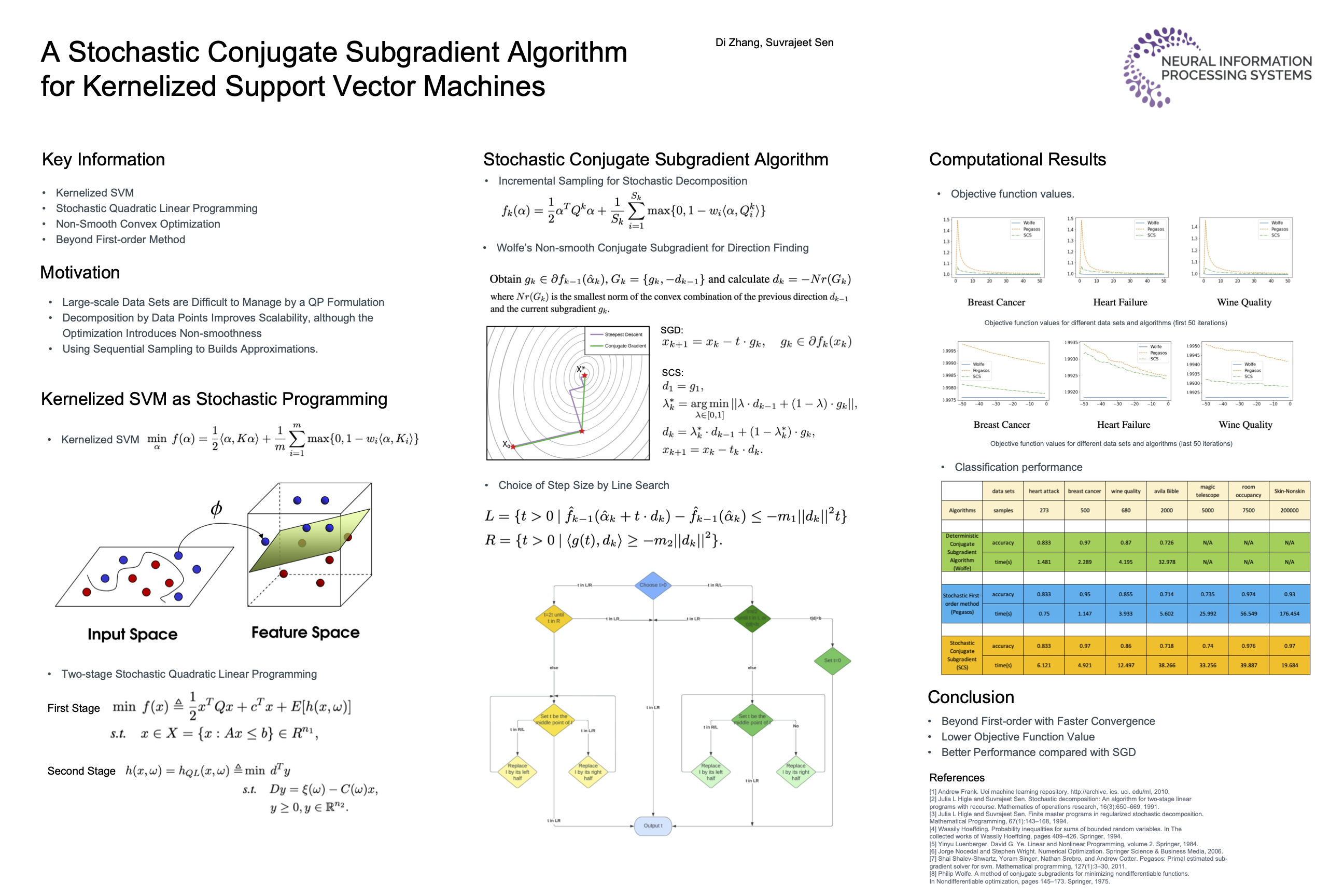
A Stochastic Conjugate Subgradient Algorithm for Kernelized Support Vector Machines: The Evidence
[
Poster]
{kind=link}
{kind=link}
{kind=link}
None
DRSOM: A Dimension Reduced Second-Order Method
None
Trust-Region Sequential Quadratic Programming for Stochastic Optimization with Random Models: First-Order Stationarity
[
Poster]
{kind=link}
{kind=link}
None
Distributed Newton-Type Methods with Communication Compression and Bernoulli Aggregation
[
Poster]
{kind=link}
{kind=link}
None
Fully Stochastic Trust-Region Sequential Quadratic Programming for Equality-Constrained Optimization Problems
[
Poster]
{kind=link}
{kind=link}
None
Using quadratic equations for overparametrized models
None
Alternating minimization for generalized rank one matrix sensing: Sharp predictions from a random initialization
[
Poster]
{kind=link}
{kind=link}
None
Quartic Polynomial Sub-problem Solutions in Tensor Methods for Nonconvex Optimization
[
Poster]
{kind=link}
None
FLECS-CGD: A Federated Learning Second-Order Framework via Compression and Sketching with Compressed Gradient Differences
None
Statistical and Computational Complexities of BFGS Quasi-Newton Method for Generalized Linear Models
[
Poster]
{kind=link}
None
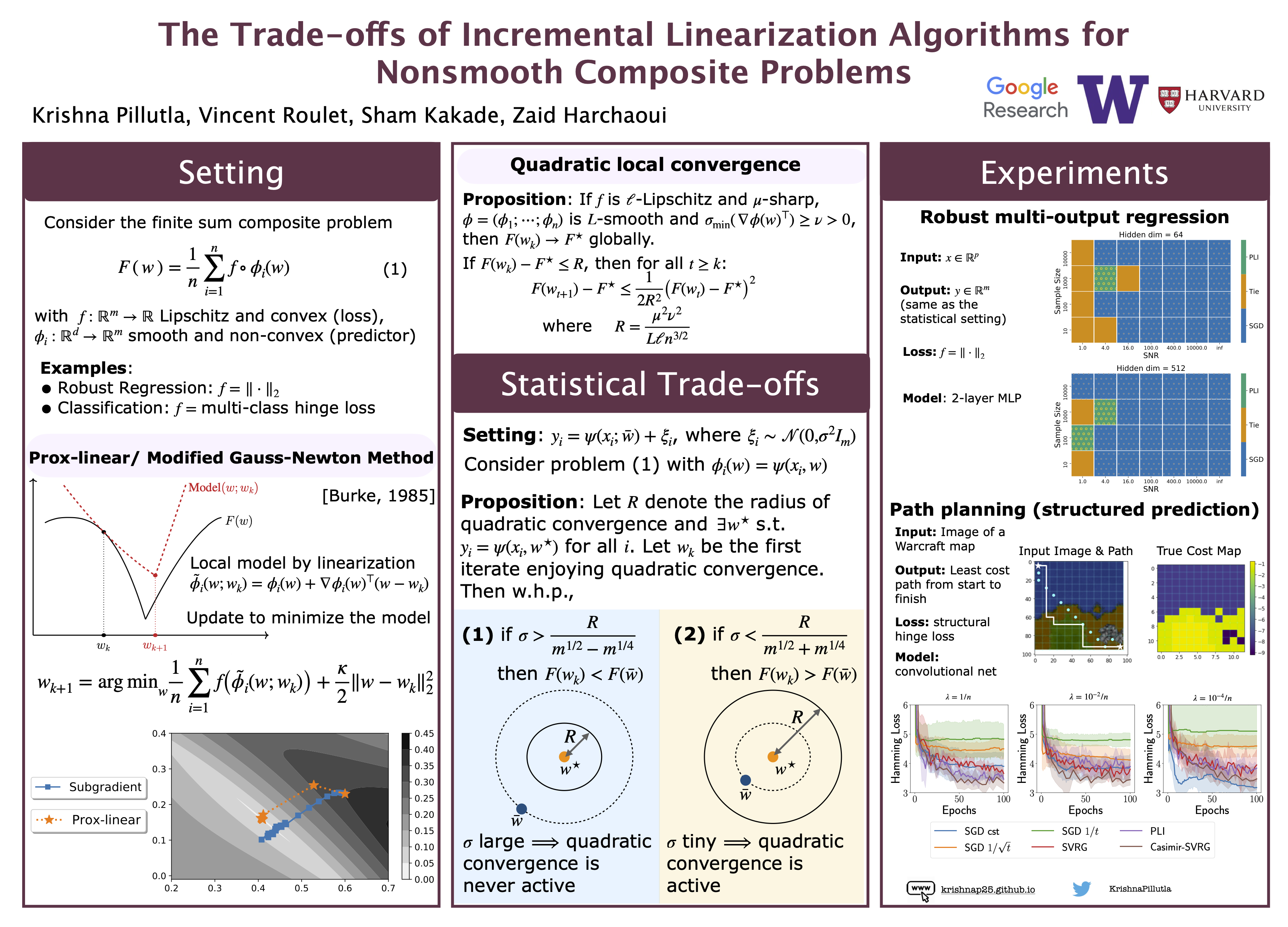
The Trade-offs of Incremental Linearization Algorithms for Nonsmooth Composite Problems
[
Poster]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Successful Page Load