Explainable Representations of Human Interaction: Engagement Recognition model with Video Augmentation
{kind=link}
Abstract
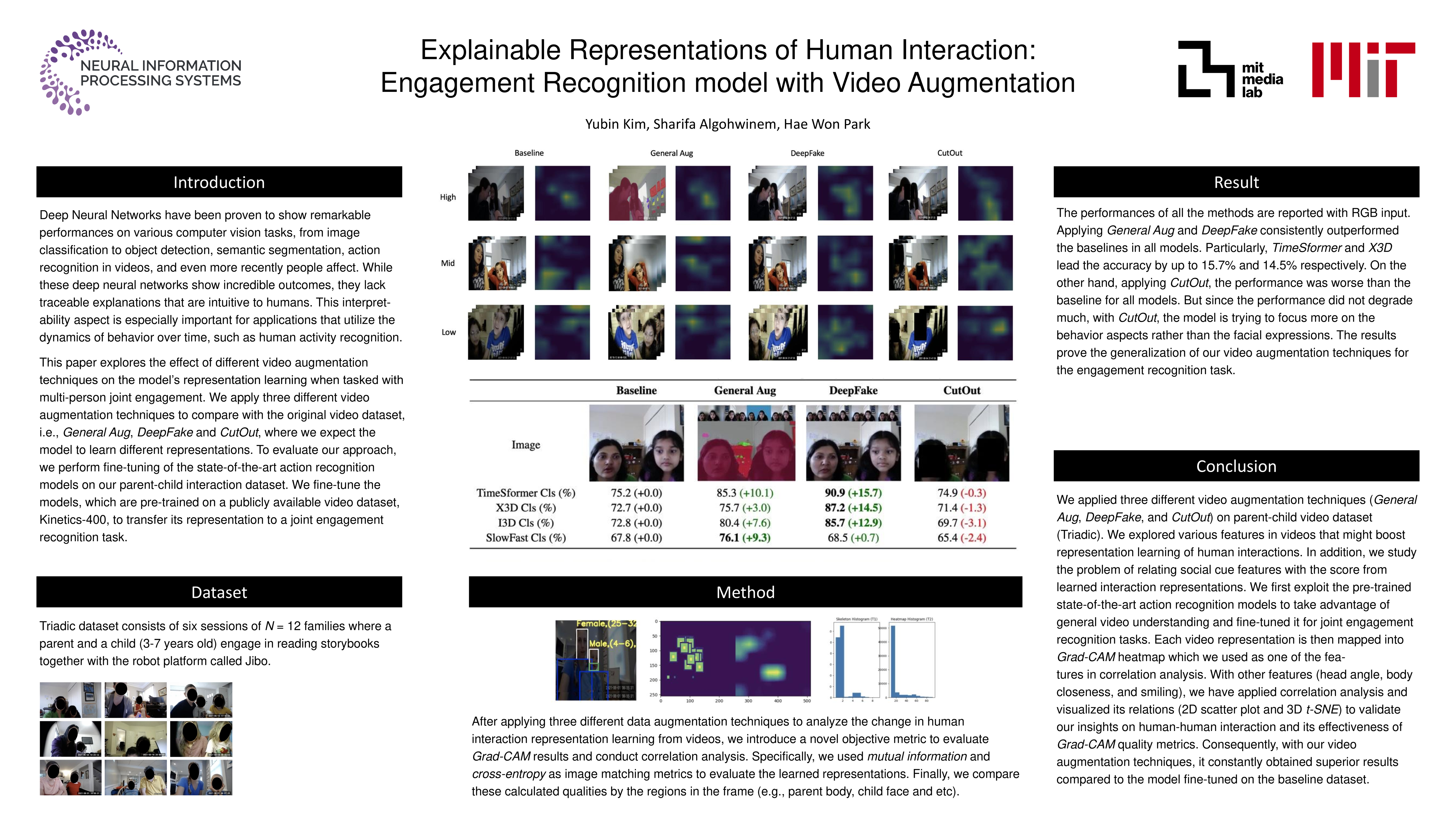
In this paper, we explore how different video augmentation techniques transition the representation learning of a dyad’s joint engagement. We evaluate state-of-the-art action recognition models (TimeSformer, X3D, I3D, and SlowFast) on parent-child interaction video dataset with joint engagement recognition task and demonstrate how the performance varies by applying different video augmentation techniques (General Aug, DeepFake, and CutOut). We also introduce a novel metric to objectively measure the quality of learned representations (Grad-CAM) and relate this with social cues (smiling, head angle, and body closeness) by conducting correlation analysis. Furthermore, we hope our method serves as a strong baseline for future human interaction analysis research.