EvoOpt: an MSA-guided, fully unsupervised sequence optimization pipeline for protein design
{kind=link}
Abstract
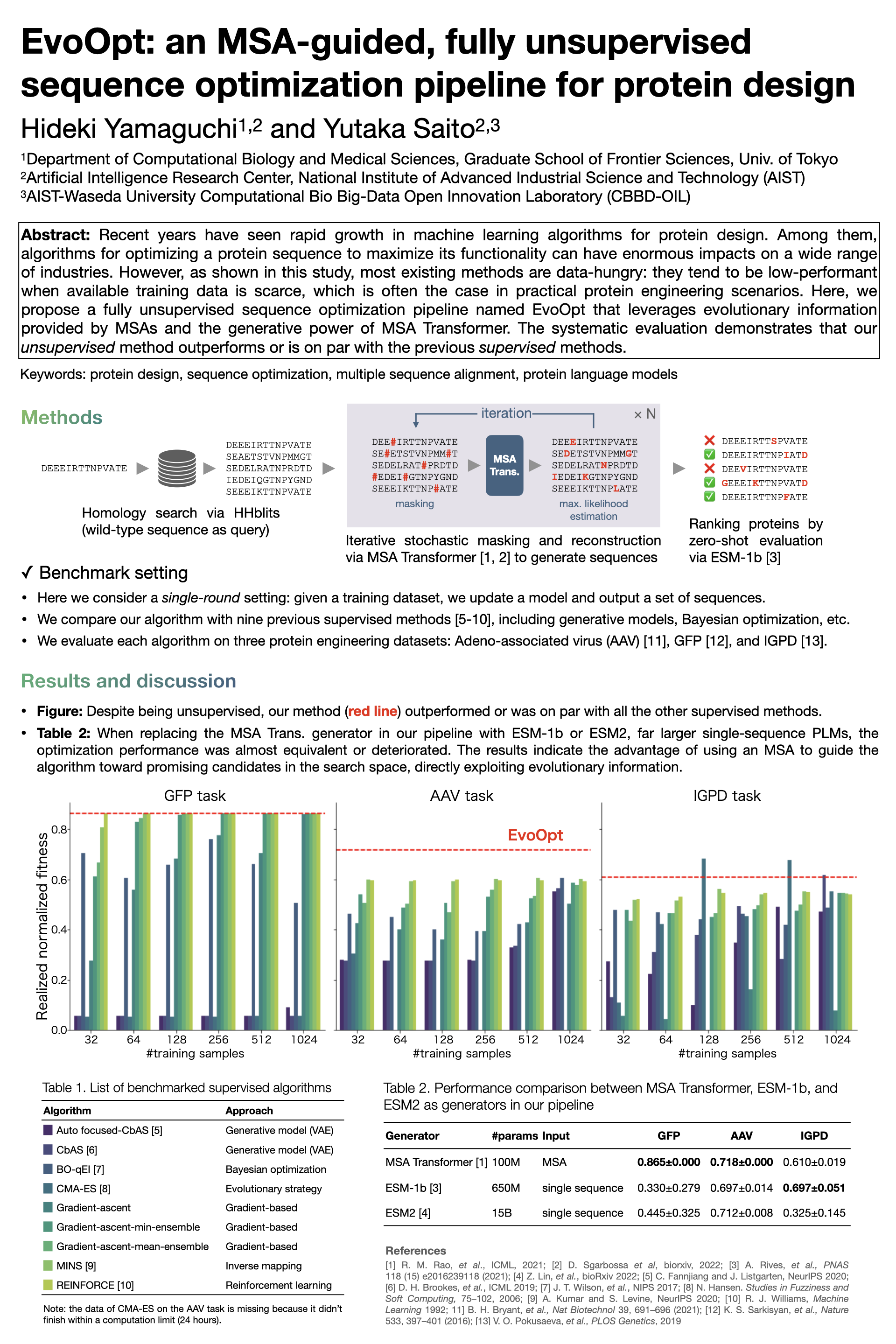
Recent years have seen rapid growth in machine learning algorithms for protein design. Among them, protein sequence optimization methods to maximize molecular functionality can significantly impact many industries. However, as shown in this study, most existing methods are data-hungry: they tend to be low-performant when available training data is scarce (i.e., in a low-N regime), which is often the case in practical protein engineering scenarios. In response, here we examine the extreme case: what if we have no training data? To answer, we propose a fully unsupervised sequence optimization pipeline named EvoOpt that leverages evolutionary information provided by multiple sequence alignments (MSAs) and the generative power of MSA Transformer, a protein language model (PLM) that takes an MSA as input. The extensive evaluation herein demonstrates that EvoOpt outperforms or is on par with the existing supervised methods even in relatively high-N regimes. We also report that the optimization performance with MSA Transformer is almost equivalent to or superior to that with a PLM that takes a single sequence as input, such as ESM-1b or ESM2 of far more model parameters. These results indicate the advantage of using an MSA to guide an algorithm toward promising candidates in the search space, directly exploiting evolutionary information.