Are AlphaZero-like Agents Robust to Adversarial Perturbations?
{kind=link}
Abstract
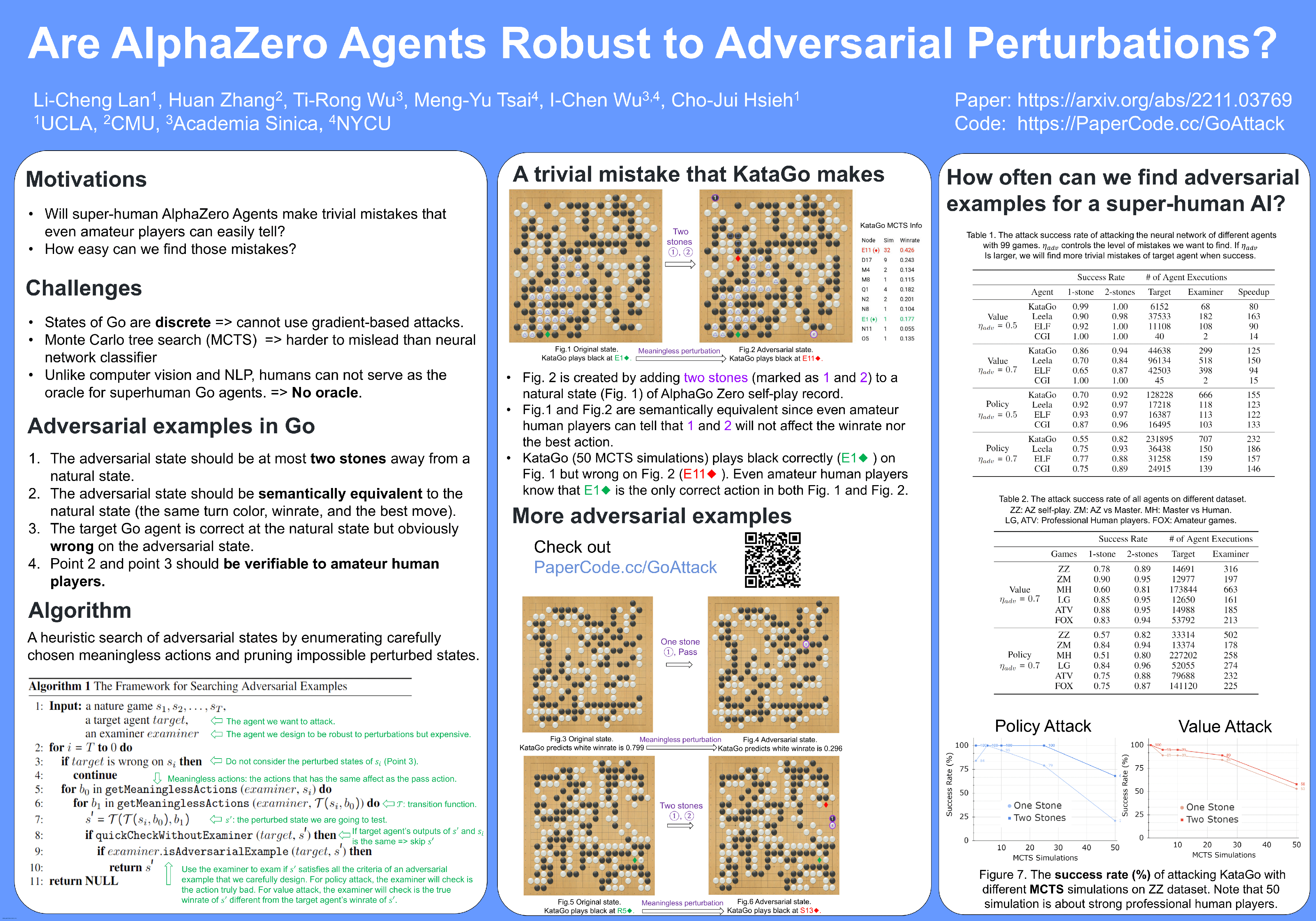
The success of AlphaZero (AZ) has demonstrated that neural-network-based Go AIs can surpass human performance by a large margin. Given that the state space of Go is extremely large and a human player can play the game from any legal state, we ask whether adversarial states exist for Go AIs that may lead them to play surprisingly wrong actions.In this paper, we first extend the concept of adversarial examples to the game of Go: we generate perturbed states that are ``semantically'' equivalent to the original state by adding meaningless moves to the game, and an adversarial state is a perturbed state leading to an undoubtedly inferior action that is obvious even for Go beginners. However, searching the adversarial state is challenging due to the large, discrete, and non-differentiable search space. To tackle this challenge, we develop the first adversarial attack on Go AIs that can efficiently search for adversarial states by strategically reducing the search space. This method can also be extended to other board games such as NoGo. Experimentally, we show that the actions taken by both Policy-Value neural network (PV-NN) and Monte Carlo tree search (MCTS) can be misled by adding one or two meaningless stones; for example, on 58\% of the AlphaGo Zero self-play games, our method can make the widely used KataGo agent with 50 simulations of MCTS plays a losing action by adding two meaningless stones. We additionally evaluated the adversarial examples found by our algorithm with amateur human Go players, and 90\% of examples indeed lead the Go agent to play an obviously inferior action. Ourcode is available at \url{https://PaperCode.cc/GoAttack}.