SPoVT: Semantic-Prototype Variational Transformer for Dense Point Cloud Semantic Completion
{kind=link}
Abstract
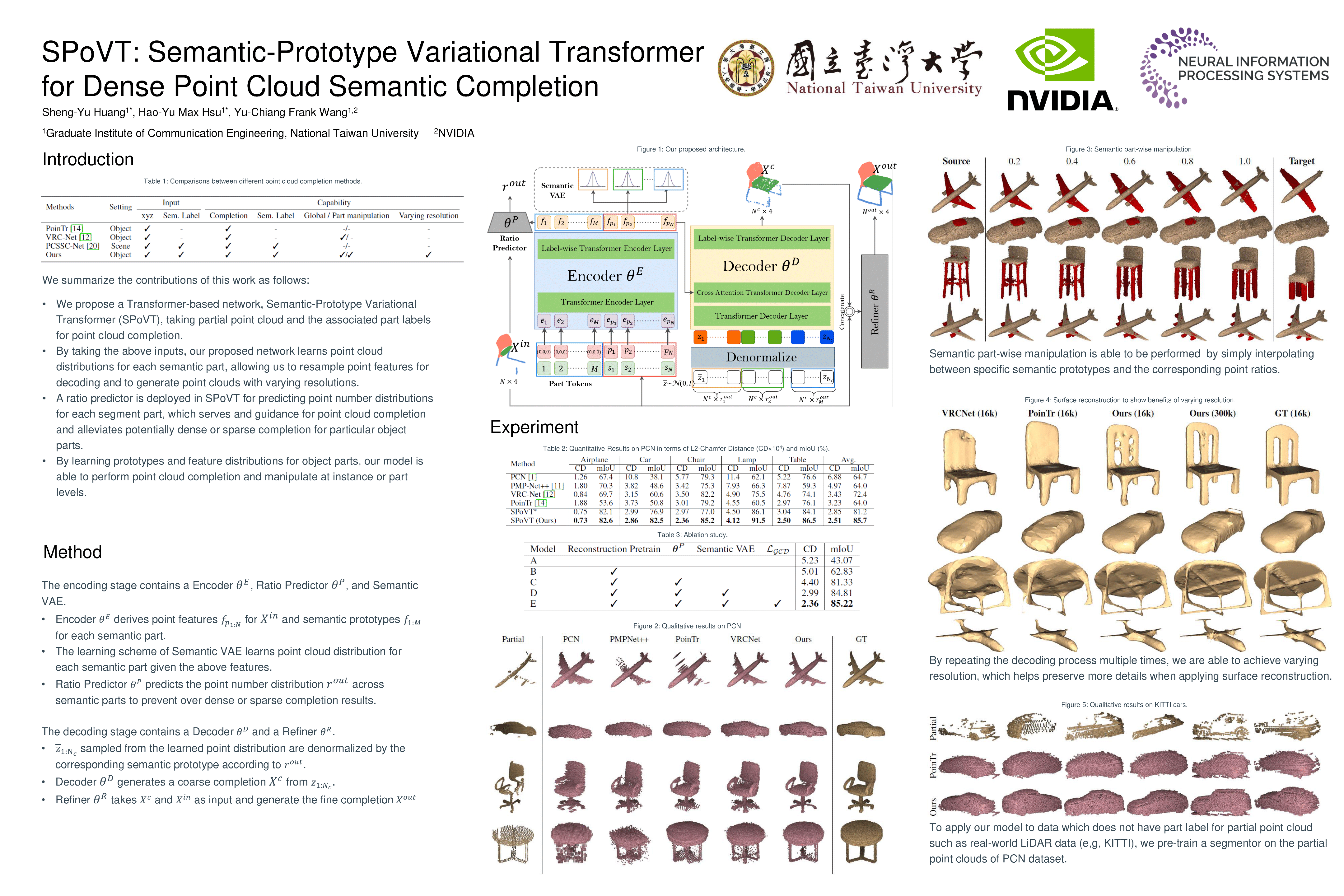
Point cloud completion is an active research topic for 3D vision and has been widelystudied in recent years. Instead of directly predicting missing point cloud fromthe partial input, we introduce a Semantic-Prototype Variational Transformer(SPoVT) in this work, which takes both partial point cloud and their semanticlabels as the inputs for semantic point cloud object completion. By observingand attending at geometry and semantic information as input features, our SPoVTwould derive point cloud features and their semantic prototypes for completionpurposes. As a result, our SPoVT not only performs point cloud completion withvarying resolution, it also allows manipulation of different semantic parts of anobject. Experiments on benchmark datasets would quantitatively and qualitativelyverify the effectiveness and practicality of our proposed model.