Digging into the (Internet) Archive: Examining the NSFW Model Behind the 2018 Tumblr Purge
{kind=link}
Abstract
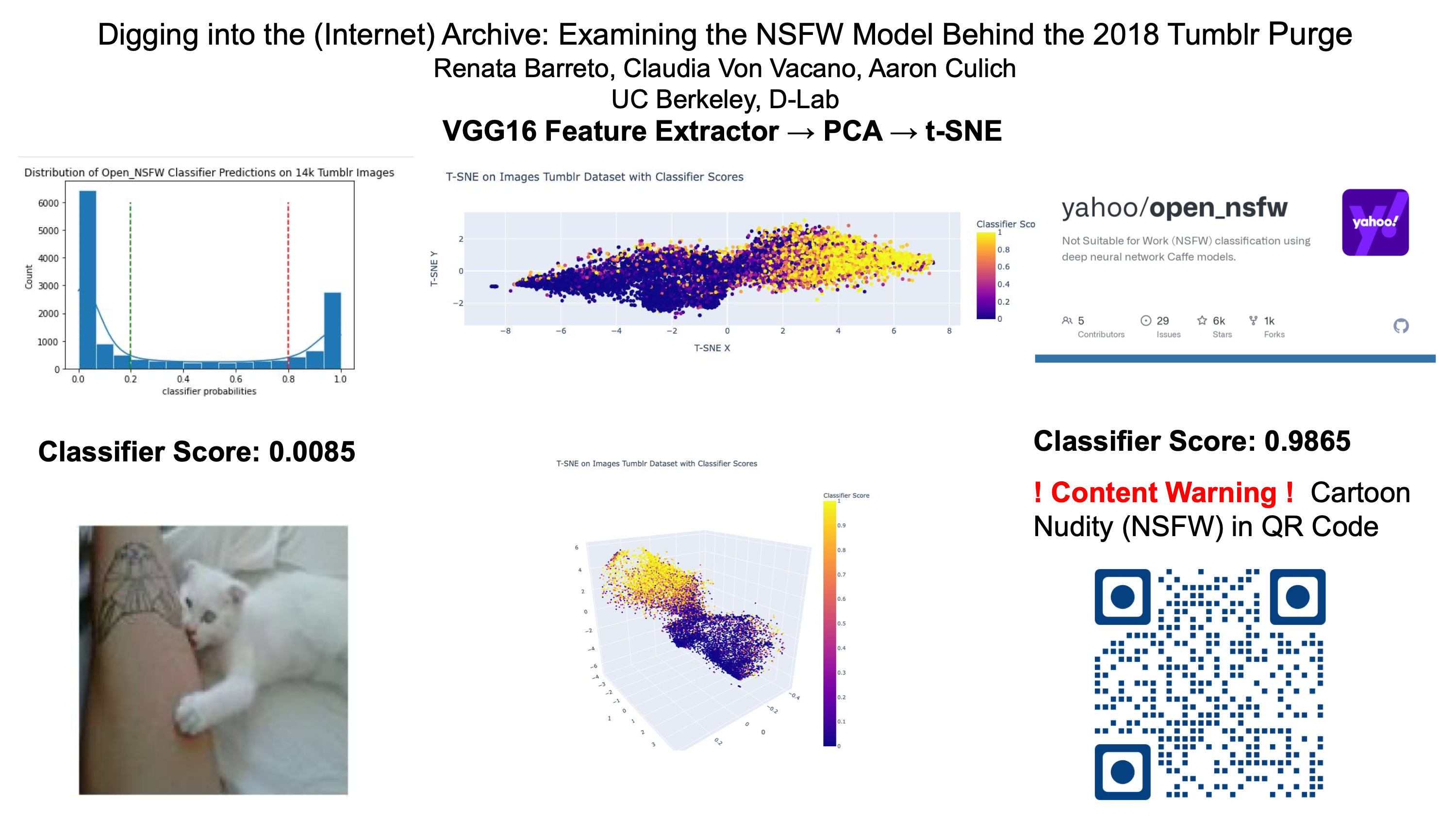
In December 2018, Tumblr took down massive amounts of LGBTQ content from its platform. Motivated in part by increasing pressures from financial institutions and a newly passed law -- SESTA / FOSTA, which made companies liable for sex trafficking online -- Tumblr implemented a strict "not safe for work" or NSFW model, whose false positives included images of fully clothed women, handmade and digital art, and other innocuous objects, such as vases. The Archive Team, in conjunction with the Internet Archive, jumped into high gear and began to scrape self-tagged NSFW blogs in the 2 weeks between Tumblr's announcement of its new policy and its algorithmic operationalization. At the time, Tumblr was considered a safe haven for the LGBTQ community and in 2013 Yahoo! bought Tumblr for 1.1 billion. In the aftermath of the so-called "Tumblr purge," Tumblr lost its main user base and, as of 2019, was valued at 3 million. This paper digs into a slice of the 90 TB of data saved by the Archive Team. This is a unique opportunity to peek under the hood of Yahoo's opennsfw model, which experts believe was used in the Tumblr purge, and examine the distribution of false positives on the Archive Team dataset. Specifically, we run the opennsfw model on our dataset and use the t-SNE algorithm to project the similarities across images on 3D space. We also labeled our 100,000 image dataset by LGBTQ community members on a Likert scale on the following dimensions: 1) does the image depict nudity or sex? 2) does the image contain or refer to LGBTQ relationships, themes, or subjects? This labeled data is only used to evaluate bias in the porn classifier and to help measure the impact of the Tumblr purge on the LGBTQ community.